第12章 Pod调度
官方文档:
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/#node-affinity
1.nodeSelector
nodeSelector 是节点选择约束的最简单推荐形式。
nodeSelector 是 PodSpec 的一个字段。 它包含键值对的映射。
为了使 pod 可以在某个节点上运行,该节点的标签中 必须包含这里的每个键值对(它也可以具有其他标签)。
最常见的用法的是一对键值对
2.亲和性和反亲和性
亲和性和反亲和性调度介绍
Pod调度有几种特性,分别为:
节点亲和性:nodeAffinity
Pod亲和性:podAffinity
Pod反亲和性:podAntiAffinity
亲和调度可以分为软需求和硬需求两种:
硬需求:必须满足指定的规则才可以调度Pod到Node上(功能和nodeSelector很像,但是使用的是不同的语法),相当于硬设置。
软需求:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重(weight)用来定义执行的先后顺序.
配置参数:
软策略:preferredDuringSchedulingIgnoredDuringExecution
硬策略:requiredDuringSchedulingIgnoredDuringExecution
节点亲和性 nodeAffinity
节点亲和性 nodeAffinity主要用来控制Pod可以被调度到哪些节点已经不能被调度到哪些节点,可以进行一些逻辑判断,不单单只是简单的相等匹配。
举例:
调度条件是硬策略不调度到Master节点,软策略是优先调度到拥有disktype=SSD标签的节点。
apiVersion: apps/v1
kind: Deployment
metadata:
name: node-affinity
labels:
app: node-affinity
spec:
replicas: 4
selector:
matchLabels:
app: node-affinity
template:
metadata:
labels:
app: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
name: nginxweb
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: #硬策略
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- master
preferredDuringSchedulingIgnoredDuringExecution: #软策略
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- SSD
应用后查看结果:可以发现都调度到了node2节点,因为我们在node2节点配置了标签
[root@node1 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity-7d8cf96487-c2jzc 1/1 Running 0 4m12s 10.2.2.139 node2 <none> <none>
node-affinity-7d8cf96487-drz9h 1/1 Running 0 4m11s 10.2.2.140 node2 <none> <none>
node-affinity-7d8cf96487-nhwqv 1/1 Running 0 4m13s 10.2.2.138 node2 <none> <none>
node-affinity-7d8cf96487-wr2mq 1/1 Running 0 4m11s 10.2.2.141 node2 <none> <none>
[root@node1 affinity]#
匹配操作符解释:
In: label的值在列表中
NotIn: label的值不在列表中
Gt: label的值大于值
Lt: label的值小于值
Exists: 存在这个label
DoesNotExist: 不存在这个label

注意事项:
nodeSelectorTerms下面可以配置多个选项,满足任何一个条件就可以了
matchExpressions下面也可以配置多个选项,但是必须同时满足这些条件才能正常被调度
Pod亲和性 podAffinity
Pod亲和性主要是解决Pod可以和哪些Pod部署在同一拓扑域中的问题,所谓的拓扑域可以理解为Pod运行的区域,对于单集群来说,那么可以认为每台主机都是一个区域,可以使用主机名标签实现。
简单来说,Pod亲和性就是指如果一个Pod运行在某个节点上,那么我也得运行在这个节点上。
Pod反亲和则相反,如果某个Pod运行在某个节点上,那么我就不和他运行在同一个节点上。
首先创建一个mysql-dp:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-dp
spec:
selector:
matchLabels:
app: mysql-dp
replicas: 1
template:
metadata:
name: mysql-dp
labels:
app: mysql-dp
spec:
volumes:
- name: mysql-volume
hostPath:
path: /data/mysql
type: DirectoryOrCreate
containers:
- name: mysql-dp
imagePullPolicy: IfNotPresent
image: mysql:5.7
ports:
- name: mysql-port
containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
volumeMounts:
- mountPath: /var/lib/mysql
name: mysql-volume
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- SSD
查看运行结果:可以发现运行在node2节点
[root@node1 pod]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql-dp-6568b7498-7cjhg 1/1 Running 0 39s 10.2.2.200 node2
创建一个亲和Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dp
labels:
app: nginx-dp
spec:
replicas: 2
selector:
matchLabels:
app: nginx-dp
template:
metadata:
labels:
app: nginx-dp
spec:
containers:
- name: nginx-dp
imagePullPolicy: IfNotPresent
image: nginx
ports:
- name: http
containerPort: 80
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- mysql-dp
topologyKey: kubernetes.io/hostname
查看运行结果:
[root@node1 pod]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
TES
mysql-dp-6568b7498-7cjhg 1/1 Running 0 4m2s 10.2.2.200 node2
nginx-dp-778856f464-b9nnc 1/1 Running 0 4s 10.2.2.201 node2
nginx-dp-778856f464-gsdbq 1/1 Running 0 4s 10.2.2.202 node2
Pod反亲和性 podAntiAffinity
修改刚才的配置,这次为反亲和:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dp
labels:
app: nginx-dp
spec:
replicas: 2
selector:
matchLabels:
app: nginx-dp
template:
metadata:
labels:
app: nginx-dp
spec:
containers:
- name: nginx-dp
imagePullPolicy: IfNotPresent
image: nginx
ports:
- name: http
containerPort: 80
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- mysql-dp
topologyKey: kubernetes.io/hostname
查看运行结果:
[root@node1 pod]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
ATES
mysql-dp-6568b7498-7cjhg 1/1 Running 0 2m45s 10.2.2.200 node2
nginx-dp-6554ffbc84-v4rdf 1/1 Running 0 4s 10.2.1.223 node3
nginx-dp-6554ffbc84-zxngq 1/1 Running 0 4s 10.2.1.222 node3
总结
第一种分类:
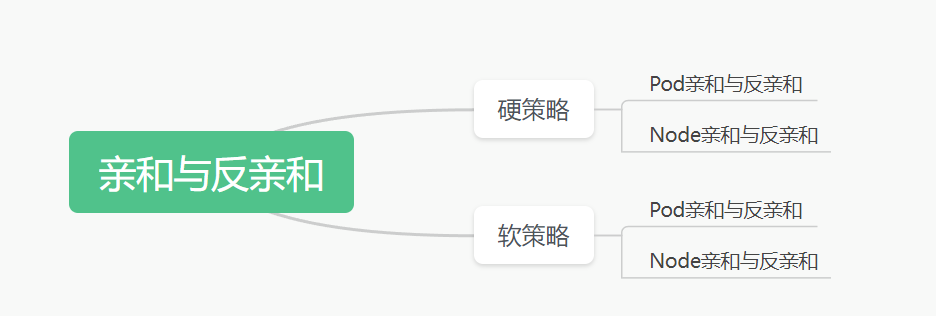
第二种分类:
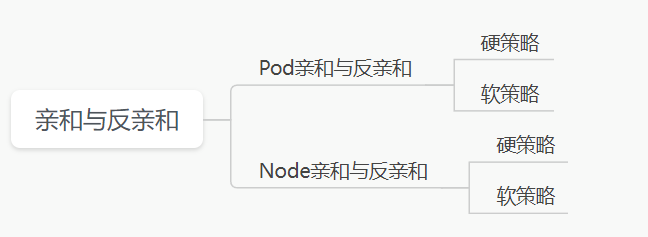
3.污点与容忍
污点
对于节点调度来说,无论是软策略还是硬策略,都是调度Pod到预期的节点上,而污点(Taints)则与之相反。
简单来说污点的作用就是说不希望Pod被调度过来,如果你硬要调度过来,那么你就要容忍污点。
我们使用kubeadm安装的集群里的master节点默认是添加了污点标记的,所以我们正常运行的pod都不会被调度到master上去。
[root@node1 ~]# kubectl describe nodes node1
Name: node1
Roles: master
Labels: app=traefik-ingress
beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=node1
kubernetes.io/os=linux
node-role.kubernetes.io/master=
..........
Taints: node-role.kubernetes.io/master:NoSchedule
Unschedulable: false
其中Taints就是污点的标记,这里写的参数是NoSchedule,表示Pod不会被调度到这个节点。
除了NoSchedule以外,还有另外两个参数选项:
- PreferNoSchedule:NoSchedule的软策略,表示尽量不被调度到有污点的节点
- NoExecute:该选项意味着一旦Taints生效,如果该节点内正在运行的Pod没有对应的容忍设置,则会直接被驱逐。
污点添加命令:
kubectl taint nodes node2 key=value:NoSchedule
举例:
kubectl taint nodes node2 test=node2:NoSchedule
查看效果:
[root@node1 ~]# kubectl describe nodes node2 |grep Taints
Taints: test=node2:NoSchedule
容忍
如果需要Pod可以被调度到设置了污点的节点,需要在Pod的资源配置清单里添加容忍污点的相关配置,下面的配置意思为可以容忍(tolerations)具有该污点(Taint)的Node.
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
参数解释:
Pod的Toleration生命的key和effect需要和Taint的设置保持一致,并且满足以下条件之一。
- 如果operator的值是Exists,则value的属性可以省略。
- 如果operator的值是Equal,则表示其key和value之间的关系是等于。
- 如果不指定operator的属性,则默认为Equal。
另外,还有两个特例:
- 空的key如果再配合Exists就能匹配所有的key与value,也就是能容忍所有节点的所有Taints。
- 空的effect匹配所有的effect
举例:这个Pod可以容忍具有污点为test的node节点。
apiVersion: apps/v1
kind: Deployment
metadata:
name: taint
labels:
app: taint
spec:
replicas: 3
selector:
matchLabels:
app: taint
template:
metadata:
labels:
app: taint
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 80
tolerations:
- key: "test" #这里和node节点的污点的名字一样
operator: "Exists" #匹配test的任何属性
effect: "NoSchedule" #匹配污点的效果
执行后可以发现可以被调度到设置了污点的node2上
[root@node1 ~]# kubectl get pod -o wide
taint-ddd44544-jgdlk 1/1 Running 0 31m 10.2.2.156 node2
taint-ddd44544-ktd5x 1/1 Running 0 31m 10.2.1.168 node3
taint-ddd44544-wgn57 1/1 Running 0 30m 10.2.2.157 node2
取消污点
如果我们想取消污点,执行以下命令
[root@node1 ~]# kubectl taint node node2 test-
node/node2 untainted
4.Node节点下线维护流程
下线流程
如果我们的Node节点需要关机维护,那么这时候正确的处理流程应该是如何呢?我们首先要确保新的Pod不会被调度到需要下线的节点,其次再将需要下线的节点上的Pod驱逐到其他节点上,等维护好之后再重新配置可以调度。流程梳理如下:
1.配置该Node不可被调度
2.驱逐Node上正在运行的Pod
3.下线节点进行维护
4.维护好后开机启动服务
5.恢复该Node可以被正常调度
设置节点不可被调度
kubectl cordon node2
驱逐节点的Pod
前面提到的NoExecute这个Taint效果对节点上正在运行的Pod有以下影响:
- 没有设置NoExecute的Pod会立刻被驱逐
- 配置了对应Toleration的Pod,如果没有为tolerationSeconds赋值,则会一直留在这一节点中。
kubectl taint node node2 test=node2:NoExecute
节点重新被调度
kubectl uncordon node2
5.安全驱逐节点
通过上节的实验我们已经掌握了如何限制Pod的调度,其实还有更简单的命令可以安全的驱逐Pod并下线Node,这条命令就是kubectl drain
官方地址:
https://kubernetes.io/zh/docs/tasks/administer-cluster/safely-drain-node/
说明:
在对节点执行维护(例如内核升级、硬件维护等)之前, 可以使用 kubectl drain 从节点安全地逐出所有 Pods。 安全的驱逐过程允许 Pod 的容器 体面地终止, 并确保满足指定的 PodDisruptionBudgets。
操作命令:
kubectl drain <nodename>
执行效果:
[root@node1 ~]# kubectl drain node3
node/node3 already cordoned
error: unable to drain node "node3", aborting command...
There are pending nodes to be drained:
node3
cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/kube-flannel-ds-gzmxp, kube-system/kube-proxy-cfhwj, monitoring/node-exporter-4f9hz
cannot delete Pods with local storage (use --delete-local-data to override): kube-system/metrics-server-5dbcdf9f85-vx5k2, kube-system/traefik-6488cd4b75-n7dfr, monitoring/alertmanager-main-1, monitoring/grafana-6ccd8d89f8-n2wqz, monitoring/prometheus-adapter-5df846c94f-5hlhn, monitoring/prometheus-adapter-5df846c94f-5mwvx, monitoring/prometheus-k8s-0, monitoring/prometheus-k8s-1
这里报错了,提示我们不能执行驱逐命令,原因有2:
1.这个节点上运行DaemonSet类型的Pod,这里为kube-flannel和kube-proxy
2.这个节点上有local存储类型的Pod,这里为prometheus的组件
如果我们想继续驱逐,需要通过以下命令设置忽略DaemonSet和local存储
kubectl drain node3 --ignore-daemonsets --delete-local-data
检查效果:
坑:这里驱逐之后提示报错,原因是因为prometheus节点必须要保持有1个在运行,但是另一个Pod还没有准备好,所以不允许被删除。解决方法就是扩容或缩容,使其满足运行的条件。
evicting pod monitoring/prometheus-k8s-1
error when evicting pod "prometheus-k8s-1" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod monitoring/prometheus-k8s-1
error when evicting pod "prometheus-k8s-1" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod monitoring/prometheus-k8s-1
error when evicting pod "prometheus-k8s-1" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod monitoring/prometheus-k8s-1
error when evicting pod "prometheus-k8s-1" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod monitoring/prometheus-k8s-1
error when evicting pod "prometheus-k8s-1" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
6.驱逐后不平衡
更新: 2024-09-06 14:12:55