20-Linux进程管理
第1章 进程管理
1.程序和进程
程序/进程的关系
开发写好的代码,没有运行的时候,只是静态的文件,我们称之为程序,程序是数据和指令的集合。
当我们把开发好的代码程序运行起来的时候,我们称之为进程。
程序运行的时候系统会为进程分配PID,运行用户,分配内存等资源。
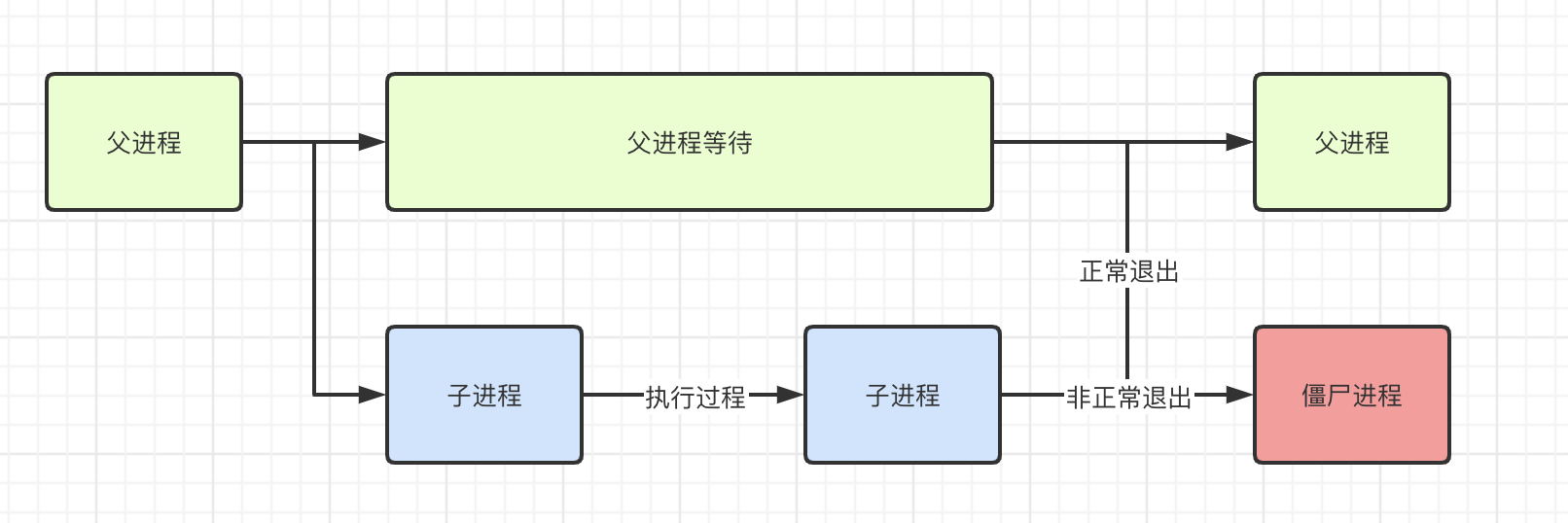
进程的生命周期
当程序运行的时候会由父进程通过fock创建子进程来处理任务。
子进程被创建后开始处理任务,当任务处理完毕后就会退出,然后子进程会通知父进程来回收资源。
如果子进程处理任务期间,父进程意外终止了,那么这个子进程就变成了僵尸进程。
如何查看当前中端的进程号和父进程号
查看当前进程号:echo $BASHPID
查看父进程号:echo $PPID
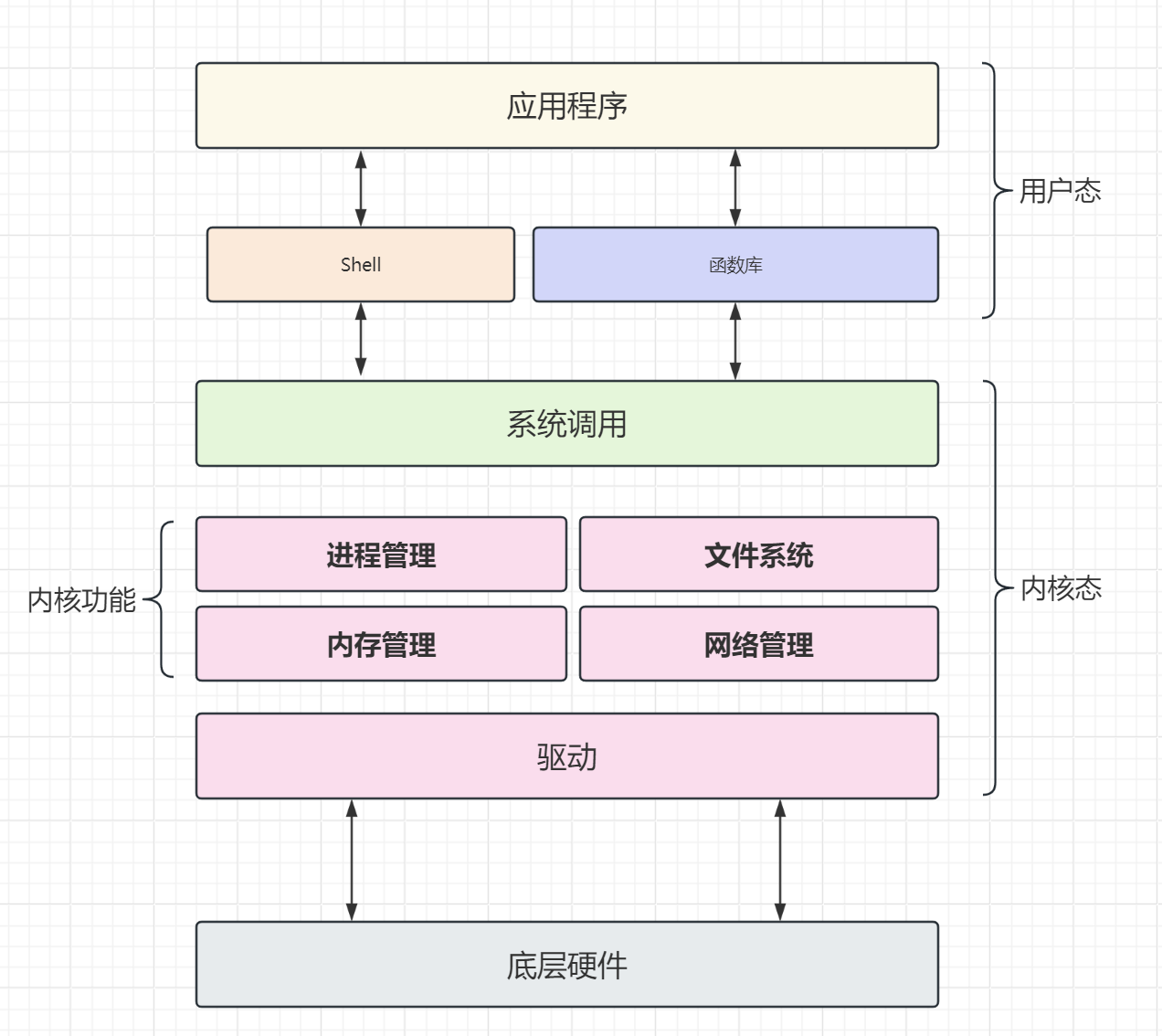
2.用户态(User Mode)和内核态(Kernel Mode)
在Linux系统中,用户态(User Mode)和内核态(Kernel Mode)是两种不同的执行模式,它们主要用于控制硬件资源访问的权限和程序执行的安全。这两种模式的区分是现代操作系统中实现安全和稳定运行的关键特性。
用户态(User Mode)
- 权限与访问控制:用户态是权限较低的执行模式,用户程序在此模式下运行。用户态程序不能直接访问硬件资源,必须通过系统调用(System Call)接口向操作系统请求服务,如读写文件、请求网络资源或启动新进程。
- 功能:用户态主要用于执行普通的应用程序代码,如文本编辑器、游戏和网络浏览器等。这些应用程序通过操作系统提供的接口与硬件交互。
- 安全性:用户态提供了一个相对安全的环境,限制了程序的执行权限,从而减少了一个程序错误可能影响整个系统的风险。如果用户态程序崩溃,通常只影响该程序本身,不会影响系统的稳定性。
内核态(Kernel Mode)
- 权限与访问控制:内核态是操作系统中具有最高权限的执行模式。在这种模式下,CPU可以直接访问所有的硬件资源,包括内存、外设和CPU指令集的特权指令。
- 功能:内核态主要用于执行操作系统的核心部分,如内核本身、驱动程序和系统服务。这些组件需要直接管理和控制硬件设备,例如文件系统的管理、网络通信、内存管理和进程调度。
- 安全风险:由于内核态代码可以执行任何指令并访问所有硬件资源,因此任何在内核态发生的错误,如内存访问错误或驱动程序的故障,都可能导致整个系统的崩溃或安全漏洞。
CPU从用户态到内核态的切换
CPU从用户态到内核态的切换通常发生在应用程序请求操作系统的服务时(比如读写文件、网络通信等),或者当发生硬件中断时(如按下键盘)。这个切换是这样的:
- 假设你在用文档编辑器工作,突然想保存文件。编辑器本身运行在用户态,但保存文件需要访问硬盘,这需要内核态权限。
- 你点击“保存”后,编辑器会通过一个系统调用请求操作系统帮助保存文件。这时,CPU会从用户态切换到内核态。
- 操作系统在内核态接管,完成对硬盘的写操作。
- 一旦操作完成,操作系统会将CPU权限切换回用户态,让编辑器继续运行。
3.进程监控命令
那么在程序运行后,我们如何了解进程运行的各种状态呢?这里我们使用一个压测工具来模拟内存,CPU,硬盘的压力产生。
stress 压测工具
介绍:
stress 是一个用于压力测试系统资源(如CPU、内存和硬盘)的工具。通过命令行选项,用户可以指定产生特定类型负载的工作进程数量,以及这些进程的行为,从而评估系统在高负荷下的表现。
安装:
yum install stress -y
查看帮助:
stress --help
解释:
Usage: stress [OPTION [ARG]] ...
-?, --help show this help statement
--version show version statement
-v, --verbose be verbose
-q, --quiet be quiet
-n, --dry-run show what would have been done
-t, --timeout N timeout after N seconds
--backoff N wait factor of N microseconds before work starts
-c, --cpu N spawn N workers spinning on sqrt()
-i, --io N spawn N workers spinning on sync()
-m, --vm N spawn N workers spinning on malloc()/free()
--vm-bytes B malloc B bytes per vm worker (default is 256MB)
--vm-stride B touch a byte every B bytes (default is 4096)
--vm-hang N sleep N secs before free (default none, 0 is inf)
--vm-keep redirty memory instead of freeing and reallocating
-d, --hdd N spawn N workers spinning on write()/unlink()
--hdd-bytes B write B bytes per hdd worker (default is 1GB)
压测CPU:
stress --cpu 8
压测内存:
stress --vm 4 --vm-bytes 128M
压测硬盘:
stress --io 2 --hdd 4
ps 查看当前的进程状态--每天都用到
命令作用:
ps process state 进程状态
打印出进程当前运行的状态快照,并不是实时的监控,而是某一时刻系统进程的快照
常用参数:
#UNIX风格
a #显示包含所有终端中的进程
u #此选项使ps列出您拥有的所有进程(与ps相同的EUID),或与a选项一起使用时列出所有进程。
x #显示进程所有者的信息
f #显示进程树
o #属性,显示定制的信息
k #属性,对属性进行排序,属性前加-表示倒叙
--sort #同上
#使用标准语法查看系统上的每个进程
-e #显示所有进程
-f #显示完整格式程序信息
-p #显示pid的进程
-C #指定命令
-q #指定id
运行结果:
#ps aux
[root@linux ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 43524 3836 ? Ss 04:20 0:02 /usr/lib/systemd/
root 2 0.0 0.0 0 0 ? S 04:20 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 04:20 0:01 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 04:20 0:00 [kworker/0:0H]
#ps -ef
[root@linux ~]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:20 ? 00:00:02 /usr/lib/systemd/systemd
root 2 0 0 04:20 ? 00:00:00 [kthreadd]
root 3 2 0 04:20 ? 00:00:01 [ksoftirqd/0]
root 5 2 0 04:20 ? 00:00:00 [kworker/0:0H]
root 6 2 0 04:20 ? 00:00:01 [kworker/u256:0]

ps aux 字段解释:
USER: #启动进程的用户
PID: #进程ID号
%CPU: #进程占用的CPU百分比
%MEM: #进程占用的内存百分比
VSZ: #进程申请占用的虚拟内存大小,单位KB
RSS: #进程实际占用的物理内存实际大小,单位KB
TTY: #进程运行的终端,?表示为内核程序,与终端无关 pts/0 第一个远程终端窗口 tty1 第一个直接连接服务器的终端窗口
STAT: #进程运行中个的状态,可以man ps关键词/STATE查询详细帮助手册
###进程状态
D: 不可中断睡眠
R: 正在运行
S: 可中断睡眠
T: 进程被暂停
Z: 僵尸进程
###进程字符
<: 高优先级进程 S<表示优先级较高的进程
N: 低优先级进程 SN表示优先级较低的进程
s: 子进程发起者 Ss表示父进程
l: 多线程进程 Sl表示进程以多线程运行
+: 前台进程 R+表示该进程在前台运行,一旦终止,数据丢失
START: #进程启动时间
TIME: #进程占用CPU时间总计
COMMAND: #程序运行的指令 []表示属于内核态的进程。没有[]表示用户态进程
ps -ef 字段解释:
UID: 运行该进程的用户的用户ID。
PID: 进程ID。
PPID: 父进程ID(Parent PID)。
C: CPU使用率,通常较低,高值可能表示CPU繁忙。
STIME: 进程启动时间。
TTY: 该进程在哪个终端上运行。如果没有终端,则显示为 ?。
TIME: 该进程占用的CPU时间。
CMD: 启动进程的命令或执行的程序。
什么是可中断(Interruptible)和不可中断(Uninterruptible)
可中断状态,通常表示为 'S' (Sleeping) 状态,是指进程正在等待某个条件的满足或某个资源的可用性,而这个等待是可以被系统中断信号打断的。例如,进程可能在等待用户输入、文件系统操作的完成或网络数据的到达。
- 特点:处于可中断睡眠状态的进程被标记为 "S" 状态。这些进程在接收到一个信号时可以被唤醒,因此它们对系统管理和用户交互是响应的。
- 优点:这允许操作系统有效管理资源,如需要时能够重新分配等待中的资源或处理高优先级的任务。
不可中断状态,通常表示为 'D' (Uninterruptible Sleep) 状态,是指进程正在执行某些关键的I/O操作,这种状态下的进程不能被信号所中断。这主要是为了防止数据的一致性和完整性问题,例如在进行磁盘操作或网络操作时。
- 特点:处于不可中断睡眠状态的进程被标记为 "D" 状态。这些进程即使收到信号也不会被唤醒,直到它们正在等待的事件完成。
- 缺点:由于这种状态下的进程不响应信号,它们有可能成为系统的潜在僵尸进程,特别是在其等待的事件由于某些原因无法完成时。
案例演示:
#1.查看进程的父子关系
ps auxf
#2.查看进程的特定属性
ps axo pid,cmd,%cpu,%mem
#3.按CPU利用率排序
ps axo pid,cmd,%cpu,%mem k -%cpu
#4.按内存使用倒序排序
ps axo pid,cmd,%cpu,%mem --sort %mem
#5.列出指定用户名和或用户ID的进程
ps -fu luffy
ps -fu 1000
#6.查看指定进程ID对应的进程
ps -fp PID
#7.查找指定父进程ID下的所有的子进程
ps -f --ppid PID
#8.按照tty显示所属进程
ps -ft pts/1
#9.根据进程名查找所属PID
ps -C sshd -o pid=
#10.根据PID查找运行的命令
ps -p PID -o comm=
模拟僵尸进程
# -*- coding: utf-8 -*-
import os
import time
def create_zombie():
pid = os.fork()
if pid > 0:
# 父进程
print("父进程,子进程的PID为: \{\}".format(pid))
# 父进程睡眠一段时间,期间不调用wait,子进程会成为僵尸进程
time.sleep(60)
print("父进程退出")
elif pid == 0:
# 子进程
print("子进程即将退出")
os._exit(0)
else:
# Fork失败
print("fork失败")
if __name__ == "__main__":
create_zombie()
pstree 以树状图查看进程状态
命令作用:
以树状图显示父进程和子进程的关系
命令格式:
pstree [选项] [pid|user]
常用参数:
-p 显示PID
-u 显示用户切换
-H pid 高亮显示指定进程
案例演示:
#1.查看指定pid的进程关系
pstree 1
#2.查看luffy用户的进程关系
pstree luffy
#3.显示pid
pstree -p
pstree -p 1
pstree -p luffy
#4.显示运行用户
pstree -u
pidof 查看指定名称进程的进程号
命令作用:
显示指定程序的pid
举例:
pidof nginx
top 查看当前的进程状态
命令作用:
展示进程动态的实时数据
常用参数:
-d #指定刷新时间,默认3秒
-n #刷新多少次后退出
-p #指定pid
内置命令:
#帮助
h/? #查看帮助
q/esc #退出帮助
#排序:
P #按CPU使用百分比排序输出
M #按内存使用百分比排序输出
#显示
1 #数字1,显示所有CPU核心的负载
m #显示内存内存信息,进度条形式
t #显示CPU负载信息,进度条形式
#退出
q #退出top命令
运行结果:
[root@linux ~]# top
top - 16:42:49 up 12:22, 3 users, load average: 0.00, 0.03, 0.05
Tasks: 106 total, 1 running, 105 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 6.2 sy, 0.0 ni, 93.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2028088 total, 465376 free, 110864 used, 1451848 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1707948 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 43524 3836 2580 S 0.0 0.2 0:02.61 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:01.45 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:01.24 kworker/u256:0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
顶部概览信息:
top- 显示当前时间、系统运行时间、登录用户数量。Tasks- 显示任务(进程)的总数,及其状态(运行、休眠、停止、僵尸)。%Cpu(s)- 显示CPU使用情况的细分,包括:- us (user) - 用户空间占用 CPU 的百分比。
- sy (system) - 内核空间占用 CPU 的百分比。
- ni (nice) - 改变过优先级的进程占用 CPU 的百分比。
- id (idle) - 空闲 CPU 百分比。
- wa (IO wait) - 等待输入输出的 CPU 时间百分比。
- hi (hardware IRQ) - 硬件中断。
- si (software IRQ) - 软件中断。
- st (steal time) - 虚拟环境中,其他操作系统占用的 CPU 时间。
MiB Mem: - 物理内存的使用情况。MiB Swap: - 交换空间的使用情况。
进程列表字段
PID- 进程ID。USER- 运行该进程的用户。PR- 优先级。NI- nice值。负值表示高优先级,正值表示低优先级。VIRT- 虚拟内存总量(KB、MB)。RES- 常驻内存大小,实际使用的物理内存(KB、MB)。SHR- 共享内存大小,多个进程可能共享的内存(KB、MB)。S- 进程状态。S(睡眠),R(运行),T(停止),Z(僵尸)。%CPU- 自上次更新以来的 CPU 使用率百分比。%MEM- 进程使用的物理内存百分比。TIME+- 该进程自启动以来的总 CPU 时间。COMMAND- 启动进程的命令行名称。
什么是软中断和硬中断?
在Linux的实现中,有两种类型的中断。
硬中断是由请求响应的设备发出的(磁盘I/O中断、网络适配器中断、键盘中断、鼠标中断)
软中断被用于处理可以延迟的任务(TCP/IP操作,SCSI协议操作等等)
简单来说,就是中断就是告诉操作系统,停下你手里的工作,先处理我的任务。
硬中断是由硬件发出的,软中断是由正在运行的进程发出的。
案例演示:
#1.查看指定pid的进程信息
top -H -p $(pidof ping)
htop 更高级的top
命令作用:
界面更美观的增强版top
常用选项:
-d #指定刷新时间
-s #以指定列字段排序
常用指令:
t #显示进程树
运行结果:
lsof 查看进程打开文件
命令作用:
查看当前系统文件的工具。
在Linux下,一切皆文件,包括硬件及网络协议等也都可以访问,系统会为每一个程序都分配一个文件描述符。
常用参数:
-c #显示指定程序名所打开的文件
-d #显示打开这个文件的进程名
-i #显示符合条件的进程,IPv[46][proto][@host|addr][:svc_list|port_list]
-p #显示指定进程pid所打开的文件
-u #显示指定用户UID的进程
+d #列出目录下被打开的文件
+D #递归累出目录下被打开的文件
状态解释:
COMMAND 进程的名称
PID 进程标识符
USER 进程所有者
FD 文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE 文件类型,如DIR、REG等
DEVICE 指定磁盘的名称
SIZE 文件的大小
NODE 索引节点(文件在磁盘上的标识)
NAME 打开文件的确切名称
案例演示:
#查看正在使用此文件的进程
lsof /var/log/nginx/access.log
#查看指定pid号的进程打开的文件
lsof -p $(cat /var/run/nginx.pid)
#查看指定程序打开的文件
lsof -c nginx
#查看指定用户打开的文件
lsof -u nginx
#查看指定目录下被打开的文件
lsof +d /var/log
lsof +D /var/log
#查看指定IP的连接
lsof -i@10.0.0.1
#查看指定进程打开的网络连接
lsof -i -a -n -p 8765
#查看指定TCP状态的连接
lsof -n -P -i TCP -s TCP:LISTEN
模拟误删除文件:
前提:被误删的文件还有进程在使用,并且这个进程不能重启或退出。
#1.新开一个终端使用tail查看nginx的访问日志,这里只是方便演示效果,不tail也可以恢复,只要nginx进程没有重启
[root@linux ~]# tail -f /var/log/nginx/access.log
#2.然后在另一个终端重看日志的进程信息
[root@linux ~]# lsof |grep access.log
nginx 9067 root 5w REG 253,0 0 67881734 /var/log/nginx/access.log
nginx 9068 nginx 5w REG 253,0 0 67881734 /var/log/nginx/access.log
tail 9099 root 3r REG 253,0 0 67881734 /var/log/nginx/access.log
#3.此时我们模拟误删除了日志文件
[root@linux ~]# rm -rf /var/log/nginx/access.log
[root@linux ~]# ll /var/log/nginx/access.log
ls: 无法访问/var/log/nginx/access.log: 没有那个文件或目录
#4.然后我们再次查看相关进程会发现日志文件后多了一个(deleted)字样,等得出PID以及文件描述符
[root@linux ~]# lsof |grep access.log
nginx 9067 root 5w REG 253,0 0 67881734 /var/log/nginx/access.log (deleted)
nginx 9068 nginx 5w REG 253,0 0 67881734 /var/log/nginx/access.log (deleted)
tail 9099 root 3r REG 253,0 0 67881734 /var/log/nginx/access.log (deleted)
#5.然后我们直接进入/proc/9067查看一下
[root@linux fd]# ll
总用量 0
lrwx------ 1 root root 64 4月 4 15:58 0 -> /dev/null
lrwx------ 1 root root 64 4月 4 15:58 1 -> /dev/null
l-wx------ 1 root root 64 4月 4 15:58 2 -> /var/log/nginx/error.log
lrwx------ 1 root root 64 4月 4 15:58 3 -> socket:[92536]
l-wx------ 1 root root 64 4月 4 15:58 4 -> /var/log/nginx/error.log
l-wx------ 1 root root 64 4月 4 15:58 5 -> /var/log/nginx/access.log (deleted)
lrwx------ 1 root root 64 4月 4 15:58 6 -> socket:[92525]
lrwx------ 1 root root 64 4月 4 15:58 7 -> socket:[92537]
#6.通过查看可以发现,名称为5的链接就是我们删除后的文件
[root@linux fd]# head -n 3 5
10.0.0.1 - - [04/Apr/2021:16:43:42 +0800] "GET / HTTP/1.1" 502 559 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36" "-"
10.0.0.1 - - [04/Apr/2021:16:43:42 +0800] "GET / HTTP/1.1" 502 559 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36" "-"
10.0.0.1 - - [04/Apr/2021:16:43:42 +0800] "GET / HTTP/1.1" 502 559 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36" "-"
#7.接着我们就可以把数据恢复出来了
[root@linux fd]# cat 5 > /var/log/nginx/access.log
[root@linux fd]# ll /var/log/nginx/access.log
-rw-r--r-- 1 root root 1194 4月 4 16:44 /var/log/nginx/access.log
4.进程管理命令
控制信号
什么是控制信号?
简单来说,就是向进程发送控制信号,一般用于停止或杀死进程。
每个信号对应1个数字,信号名称以SIG开头,可以省略SIG头。
Linux常见控制信号
信号名称 数字编号 信号含义
HUP 1 无需关闭进程并且让其重新加载配置文件
KILL 9 强制杀死正在运行的进程
TERM 15 终止正在运行的进程,不特别指定数字信号的话,默认就是15
控制进程的命令
kill #结束指定PID的进程
killall #根据进程名杀死进程
pkill #同样是根据进程名杀死进程
kill 杀死指定PID的进程
命令作用:
根据进程的pid号杀死指定的进程
常用参数:
kill -1 pid #重新加载配置
kill -15 pid #优雅的停止进程
kill -9 pid #强制终止进程
案例演示:
#1.安装nginx
[root@linux ~]# yum install nginx -y
#2.创建2个新的默认网页
[root@linux ~]# echo v1 > /usr/share/nginx/html/index.html
[root@linux ~]# cat /usr/share/nginx/html/index.html
v1
[root@linux ~]# echo v2 > /usr/share/nginx/html/index2.html
[root@linux ~]# cat /usr/share/nginx/html/index2.html
v2
#3.启动nginx并查看网页信息
[root@linux ~]# systemctl start nginx
[root@linux ~]# curl 127.0.0.1
v1
#4.修改nginx配置文件,将默认首先更新为index2.html
[root@linux ~]# sed -i 's#index.html#index2.html#g' /etc/nginx/conf.d/default.conf
[root@linux ~]# grep "index2" /etc/nginx/conf.d/default.conf
index index2.html index.htm;
#5.这时在访问一次。会发现依然是v1版本,为什么?因为我们虽然修改了配置文件,但是并没有重启,所以配置文件没有被加载。
[root@linux ~]# curl 127.0.0.1
v1
#6.查看nginx自带的启动文件里是如何重新加载配置文件的
[root@linux ~]# rpm -ql nginx |grep nginx.service
/usr/lib/systemd/system/nginx.service
[root@linux ~]# grep -i "reload" /usr/lib/systemd/system/nginx.service
ExecReload=/bin/sh -c "/bin/kill -s HUP $(/bin/cat /var/run/nginx.pid)"
#可以发现nginx重新加载配置是分为了2步操作:
1.找出正在运行的nginx的pid号
2.向nginx进程发送HUP信号,也就是0型号以使其重新加载配置
#7.发送控制信号重新加载配置
[root@linux ~]# pidof nginx
20951 20950
[root@linux ~]# cat /var/run/nginx.pid
20950
[root@linux ~]# kill -1 20950
#8.重新查看网页可以发现已经切换到了v2版本,说明配置被重新加载了
[root@linux ~]# curl 127.0.0.1
v2
#9.使用kill杀死进程
[root@linux ~]# kill 20950
[root@linux ~]# ps -ef|grep nginx
pkill和killall 杀死指定名称的进程
命令作用:
类似于kill,只不过kill需要先找出pid号,然后再杀掉进程
而pkill则可以将kill的两步操作合二为一,只需要根据进程名就可以杀死进程
不过要注意的是pkill的优势也有可能会造成误杀,因为是根据进程名杀死进程,那么只要匹配上进程名的进程,哪怕只是名称里包含了匹配的,也会被杀掉。
案例演示:
#1.启动并查看nginx
[root@linux ~]# systemctl start nginx
[root@linux ~]# ps -ef|grep nginx|grep -v grep
root 21088 1 0 16:49 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 21089 21088 0 16:49 ? 00:00:00 nginx: worker process
#2.使用pkill杀死进程
[root@linux ~]# pkill nginx
[root@linux ~]# ps -ef|grep nginx|grep -v grep
#3.重新启动nginx并查看进程
[root@linux ~]# systemctl start nginx
[root@linux ~]# ps -ef|grep nginx|grep -v grep
root 21141 1 0 16:51 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 21142 21141 0 16:51 ? 00:00:00 nginx: worker process
#4.使用killall杀死nginx进程
[root@linux ~]# killall nginx
[root@linux ~]# ps -ef|grep nginx|grep -v grep
5.进程后台管理
前台运行与后台运行
前台进程就是运行在当前的终端,并且运行中的信息都会输出到屏幕上,会一直占用终端的使用。如果当前终端关闭了,则进程就自动退出了。
而后台进程则可以在终端的后台继续运行,但是并不会占用当前的终端使用。即使当前终端关闭了,进程也不会退出。
&,jobs,bg,fg -- 了解即可
命令作用:
& #把未启动的进程放在后台执行
jobs #查看后台进程
ctrl + z #将运行中的进程放在后台.但是暂停
bg #将暂停的进程放在后台继续运行
fg #将后台进程调回到前台
案例演示:
[root@linux ~]# sleep 3000 &
[1] 22125
[root@linux ~]# sleep 4000
^Z
[2]+ 已停止 sleep 4000
[root@linux ~]# ps aux|grep sleep
root 22125 0.0 0.0 108052 612 pts/0 S 20:41 0:00 sleep 3000
root 22127 0.0 0.0 108052 616 pts/0 T 20:41 0:00 sleep 4000
[root@linux ~]# jobs
[1]- 运行中 sleep 3000 &
[2]+ 已停止 sleep 4000
[root@linux ~]# bg %2
[2]+ sleep 4000 &
[root@linux ~]# jobs
[1]- 运行中 sleep 3000 &
[2]+ 运行中 sleep 4000 &
[root@linux ~]# fg %1
sleep 3000
[root@linux ~]# kill %2
[root@linux ~]# jobs
[2]- 已终止 sleep 4000
[3]+ 运行中 sleep 3000 &
screen -- 重点推荐
命令作用:
工作中非常推荐使用的后台进程管理工具,作用是可以将进程放在后台运行,并且可以随时切换到前台。
常用参数:
screen -S 终端名称 #新建一个指定名称的终端
Ctrl + a + d #切换到前台,但是保持后台运行的进程
screen -ls #查看已经放在后台的进程名称列表
screen -r 名称或ID号 #进入指定名称的后台程序
案例演示:
#1.创建名为ping的终端
[root@linux ~]# screen -S ping
#2.切换到后台后执行前台命令
[root@linux ~]# ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.012 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.038 ms
#3.切出后台,切换到前台
Ctrl + a + d
#4.查看已经在运行的后台进程列表
[root@linux ~]# screen -ls
There is a screen on:
22237.ping (Detached)
1 Socket in /var/run/screen/S-root.
#5.重新进入指定名称的后台进程
[root@linux ~]# screen -r ping
nohub &
命令作用:
将进程放在后台执行,并且把运行过程输出到日志里。
常用参数:
nohup 命令 >> 日志 2>&1 &
案例演示:
nohup /usr/sbin/nginx >> /var/log/nginx/access.log 2>&1 &
第2章 系统负载监控
uptime 查看系统平均负载
什么是系统负载?
系统负载是用来衡量计算机性能和压力状态的指标之一。通常当我们谈论系统负载时,特别是在类Unix系统(如Linux)中,我们通常指的是“平均负载”。
这个指标表示了系统在特定时间间隔内,等待CPU资源(包括正在执行和等待CPU的任务)的平均进程数量。这个指标有助于理解计算机在过去一段时间内的工作负荷情况
注意,平均负载指的并不是系统CPU使用率。
什么是可运行状态和不可中断状态?
1.可运行状态进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们ps命令看到处于R状态的进程。
2.不可中断进程,系统中最常见的是等待硬件设备的I/O响应,也就是我们ps命令中看到的D状态(也称为 Disk Sleep)的进程。
例如: 当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
在Linux的实现中,有两种类型的中断。
硬中断是由请求响应的设备发出的(磁盘I/O中断、网络适配器中断、键盘中断、鼠标中断)。
软中断被用于处理可以延迟的任务(TCP/IP操作,SCSI协议操作等等)
平均负载为多少合适?
最理想的状态是每个CPU核上都刚好运行着一个进程,这样每个CPU都得到了充分利用。
所以首先你需要知道你的服务器上有几个CPU,可以通过lscpu命令或top交互模式按1查看有几核。
假如有以下核数的CPU,负载为2时,说明了什么?
CPU核数 负载 说明
1 2 表示有一半的进程需要等待
2 2 表示刚好所有的CPU都被使用了
4 2 表示有一半的CPU处于空闲状态
uptime命令有三个数值,分别为1,5,15分钟的平均负载,那么该如何理解这三个数值呢?或者说更应该关注哪个值?
简单来说,三个数值都要看,但是一定要分析变化的趋势,虽然三个值是数字,但是他们表达的是1到15分钟CPU负载变化的趋势。
例如如下几种情况:
1.三个数值差不多一样,这表示了系统运行很稳定,15分钟内系统没有特别繁忙。
2.如果1分钟的值大于15分钟的值,那表示系统负载1分钟内有上升的趋势。但是并不能立即下结论,因为有可能只是临时的升高,所以要持续的观察一段时间,结合这段时间的趋势分析。
3.如果1分钟负载低于15分钟的值,那表示系统负载是在下降的趋势。
如何监控系统负载的趋势呢?
实际工作中我们不可能实时的使用uptime命令来监控系统负载,那么我们如何随时系统平均的负载呢?
1.自己编写脚本然后配合定时任务周期性的运行uptime命令并输出到文本里
2.推荐使用成熟的监控工具,比如zabbix,Prometheus等监控平台,因为他们具有丰富的图形报表功能,更容易观察变化趋势。
假如平均负载变高了,应该如何处理?
虽然理想情况是每个CPU核数都被使用,但是也不是说如果平均负载超过了CPU核数系统就不正常了。
如果只是短暂的超过了CPU核数,并且平均负载有下降的趋势,那可以理解为刚才系统只是暂时的繁忙,现在已经恢复正常。
如果持续的负载高,但是业务系统并没有变慢,系统也没有进一步变糟糕的趋势,那么也不用过于担心。
如果系统确实负载高了,那么可以从以下几个角度分析:
1.运行任务是否CPU密集型
2.运行任务是不是IO密集型
命令作用:
通过uptimem命令我们可以了解到系统的CPU负载情况,当然top命令也可以。
运行结果:
[root@linux ~]# uptime
10:14:58 up 15:01, 1 user, load average: 0.01, 0.03, 0.05
状态解释:
10:14:58 #当前时间
up 15:01 #系统已启动时间
1 user #当前登陆的用户数
load average: 0.01, 0.03, 0.05 #系统 1分钟,5分钟,15分钟的平均负载
模拟CPU使用率100%的场景
这里我们使用三个工具来找出平均负载变高的原因
stress: 压测工具
mpstat: 多核CPU性能分析工具
pidstat: 实时查看CPU,内存,IO等指标
#1.安装性能监控工具
[root@linux ~]# wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.7.3-1.x86_64.rpm
[root@linux ~]# rpm -ivh sysstat-11.7.3-1.x86_64.rpm
#2.使用strss工具模拟CPU使用率100%
[root@linux ~]# stress --cpu 1 --timeout 600
stress: info: [18742] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
#3.在第2个终端运行uptime命令实时查看系统的负载
##可以看到1分钟的负载正在升高
[root@linux ~]# watch -d uptime
16:06:47 up 20:53, 3 users, load average: 0.90, 0.67, 0.51
#4.在第3个终端运行mpstat查看CPU使用率变化情况
##可以看到CPU1使用率达到了100%,但是iowait只有0,这说明系统负载变高正是由于CPU使用率100%导致的
[root@linux ~]# mpstat -P ALL 5
Linux 3.10.0-957.el7.x86_64 (linux) 2021年04月05日 _x86_64_ (1 CPU)
15时59分32秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
15时59分37秒 all 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
15时59分37秒 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
#5.在第4个终端使用top命令查看CPU使用率
##可以看到stress进程的CPU使用率达到了100%
[root@linux ~]# top
Tasks: 104 total, 2 running, 102 sleeping, 0 stopped, 0 zombie
%Cpu(s):100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2028088 total, 1590216 free, 101924 used, 335948 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1735256 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18743 root 20 0 7312 100 0 R 99.7 0.0 6:55.68 stress
18712 root 20 0 0 0 0 S 0.3 0.0 0:00.06 kworker/0:2
1 root 20 0 43528 3848 2580 S 0.0 0.2 0:03.66 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
第3章 内存监控
free 查看内存使用状态
命令作用:
查看Linux系统的内存使用情况
常用参数:
free [选项]
-b 以b为单位输出
-k 以k为单位输出
-m 以m为单位输出
-g 以g为单位输出
-h 以人类可读友好的单位输出
-s N 间隔N秒输出一次
-c N 输出N次后退出
运行结果:
#默认以b为单位输出
[root@linux ~]# free
total used free shared buff/cache available
Mem: 2028088 85188 1807080 9720 135820 1783376
Swap: 0 0 0
#以m为单位输出
[root@linux ~]# free -m
total used free shared buff/cache available
Mem: 1980 82 1764 9 132 1741
Swap: 0 0 0
#以人类可读的单位输出
[root@linux ~]# free -h
total used free shared buff/cache available
Mem: 1.9G 82M 1.7G 9.5M 132M 1.7G
Swap: 0B 0B 0B
状态解释:
man free #free命令帮助手册
total #总计已安装的内存,统计信息来自/proc/meminfo的MemTotal和SwapTotal字段
used #已使用内存,计算公式为:used = total - free - buffers - cache
free #空闲的未使用内存,计算公式为:total - used - buff - cache
shared #共享内存,主要由tmpfs使用
buff/cache #buffers和cache的总和
buffers #缓冲区,写缓冲,目的是加快内存和硬盘之间的数据写入。存放内存需要写入到磁盘的数据。
cache #缓存区,读缓存,目的是加快CPU和内存交换数据。存放的是内存已经读完的数据。
available #估计有多少内存可用于启动新应用程序而无需交换。与cache或free字段提供的数据不同,此字段考虑了页面缓存。
swap #硬盘交换分区,目的是防止内存使用完了导致系统崩溃,临时将硬盘的一部分空间当作内存使用。
total: 总计内存(单位通常是KB)。这表示系统总的可用物理内存大小。
used: 已使用的内存。这部分包括了所有已被进程占用的内存,不包括为缓冲或缓存保留的内存。
free: 空闲内存。这部分内存目前没有被使用。
shared: 多个进程共享的内存总量。这通常用于进程间的通信或者某些特殊类型的内存映射文件。
buff/cache: 为缓冲和缓存使用的内存总量。缓冲内存用于块设备的输入输出缓存,而缓存内存则用于文件系统的缓存。
available: 估计的可用内存。这是指可以不经换页(swap)直接使用的内存大小。这个值是free命令在较新版本中引入的,给出了一个比较实际的可以用于启动新应用程序的内存估计值。
清空缓存:
echo 3 > /proc/sys/vm/drop_caches
buff/cache解释:
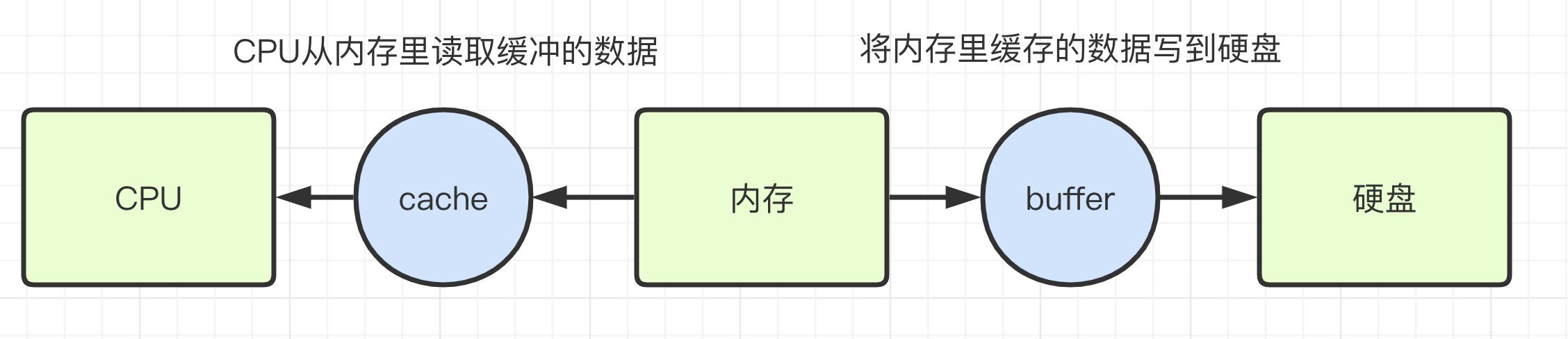
cache:
内存速度很快,但是CPU速度更快,所以为了提高CPU和内存之间交换数据的效率,设计了cache缓存这种技术。
CPU本身就有缓存,就是我们常听说的1级缓存2级缓存3级缓存,但是CPU内部的缓存成本太昂贵,所以设计的容量都非常小,那么就利用内存的部分空间来缓存CPU已经读过的数据,这样CPU下次访问只需要从cache里直接取就行了,不用再访问内存里的实际存储位置。
buffers:
内存速度很快,但是硬盘速度很慢,所以为了提高硬盘的写入效率,设计了buffer。
buffer主要作用是将内存写完的数据缓存起来,然后通过系统调度策略在合适的时机再定期刷新到磁盘上。
这样可以减少磁盘的寻址次数,以提高写入性能。
示意图:
第4章 磁盘监控
什么是磁盘I/O
磁盘I/O(输入/输出)是指数据在磁盘驱动器与计算机系统之间传输的过程。这涉及到数据的读取(从磁盘读取数据到计算机内存)和写入(将数据从计算机内存写入到磁盘)。
基本概念
- 读操作:当程序需要访问存储在磁盘上的数据时,操作系统会执行读操作。这包括查找数据位置、从磁盘读取数据,并将其加载到内存中供CPU或应用程序使用。
- 写操作:当需要保存或更新存储在磁盘上的数据时,操作系统执行写操作。这涉及将数据从内存传输到磁盘上的适当位置。
磁盘I/O的重要性
磁盘I/O性能对系统总体性能有很大影响,因为磁盘操作通常比内存或CPU操作慢得多。如果一个系统的磁盘I/O性能不佳,即使CPU和内存资源充足,系统的响应速度和数据处理能力也可能会受到严重影响。
磁盘IO压测工具
fio 是一个非常灵活的I/O性能测试工具,可以模拟多种不同类型的I/O负载,并提供详细的性能统计数据。它支持多种操作系统,包括Linux、Windows和macOS。
对于I/O压力测试,主要是要评估存储设备(如硬盘、SSD)和文件系统在高负荷下的性能。这里有几个广泛使用的I/O压力测试工具,我也会简要介绍如何使用它们:
1. fio (Flexible I/O Tester)
fio 是一个非常灵活的I/O性能测试工具,可以模拟多种不同类型的I/O负载,并提供详细的性能统计数据。它支持多种操作系统,包括Linux、Windows和macOS。
安装方法(Linux):
yum install fio
基本使用示例:
fio --name=iotest --ioengine=libaio --iodepth=4 --rw=read --bs=4k --direct=1 --size=1G --numjobs=4 --runtime=60 --group_reporting
- --name=iotest`: 测试的名称。
--ioengine=libaio: 使用Linux的异步I/O。--iodepth=4: I/O深度,表示排队的I/O数量。--rw=read: 读测试(可选write或randread等)。--bs=4k: 块大小4KB。--direct=1: 绕过缓存。--size=1G: 文件大小。--numjobs=4: 同时运行的作业数。--runtime=60: 运行时间(秒)。--group_reporting: 汇总报告。
iostat
iostat 是一个强大的工具,用于监控系统输入/输出设备的使用情况,包括硬盘、分区和文件系统等。它能够提供关于系统磁盘活动的详细报告,帮助你识别性能瓶颈。iostat 输出的字段根据是否包含 -x 选项(扩展统计信息)而有所不同。
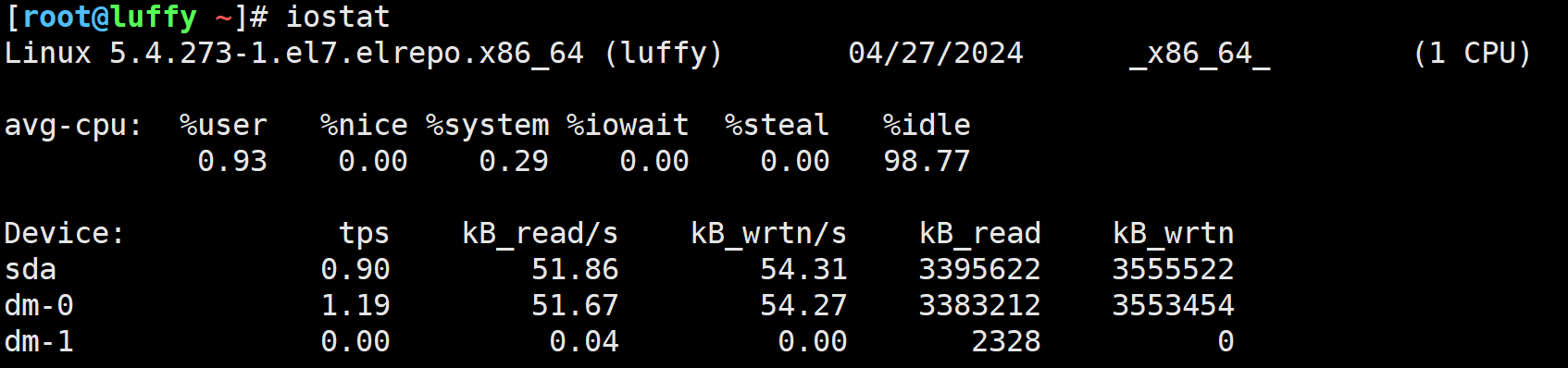
基本输出字段解释
以下是运行 iostat 命令(不带 -x 选项)时,通常会看到的字段:
- Device: 指的是物理或逻辑磁盘名。
- tps: 每秒传输次数(I/O 请求)。
- Blk_read/s (kB_read/s or MB_read/s): 每秒从设备(磁盘)读取的数据块(或KB、MB)数量。
- Blk_wrtn/s (kB_wrtn/s or MB_wrtn/s): 每秒写入设备(磁盘)的数据块(或KB、MB)数量。
- Blk_read (kB_read or MB_read): 从设备读取的总数据块数(或KB、MB)。
- Blk_wrtn (kB_wrtn or MB_wrtn): 写入设备的总数据块数(或KB、MB)。
扩展输出字段解释 (iostat -x)
使用 -x 选项,iostat 提供更详细的设备使用情况:
- rrqm/s: 每秒进行的读取合并的请求数。较高的值表示进行了有效的读取合并,这通常可以提高性能。
- wrqm/s: 每秒进行的写入合并的请求数。较高的值表示进行了有效的写入合并。
- r/s: 每秒完成的读 I/O 设备次数。
- w/s: 每秒完成的写 I/O 设备次数。
- rMB/s: 每秒读取的MB数。
- wMB/s: 每秒写入的MB数。
- avgrq-sz: 平均每次设备I/O操作的数据大小(以扇区为单位)。
- avgqu-sz: 平均I/O队列长度。显示请求的平均队列长度。
- await: 每次I/O请求的平均等待时间(以毫秒为单位),包括请求的排队时间和处理时间。
- r_await: 读请求的平均等待时间(以毫秒为单位)。
- w_await: 写请求的平均等待时间(以毫秒为单位)。
- svctm: 平均服务时间(以毫秒为单位)。仅供参考,因为现代设备的并发处理使得此值可能不准确。
- %util: 设备利用率百分比。接近100%表示设备可能成为瓶颈。
最佳实践
使用 iostat 监控磁盘性能时,应注意以下几点:
- 定期监控: 定期运行
iostat,特别是在系统负载变化时,可以帮助你及时发现性能问题。 - 持续监控: 对于生产环境,可以使用工具如
zabbix或prometheus等,结合iostat持续监控磁盘性能。 - 性能分析: 注意
%util和await字段,这些可以直接反映出设备的性能状况和潜在瓶颈。
iotop
命令作用:
iotop用于监控磁盘的I/O使用情况,包含读和写的速率,IO百分比等信息,类似于top命令。
常用参数:
-o #只显示正在进行io操作的进程,也可以先在iotop命令运行中按o
-b #非交互模式,比较适合监控项取值或者脚本定时输出内容
-n N #默认非交互模式会一直输出信息,-n选项可以控制输出次数,常结合-b参数一起使用
-d N #设置每次数据更新的间隔,默认是1秒
-p PID #监控指定PID的进程
-u USER #监控指定用户运行程序产生的IO
-q #禁止输出头几行,一般用于非交互模式
-qq #不显示列名
-qqq #不显示IO的总揽
交互式按键:
左/右键 #切换选中的列,并且按照选中的列进行排序
p #默认显示的是线程TID,按p切换到进程PID
q #退出
运行结果:
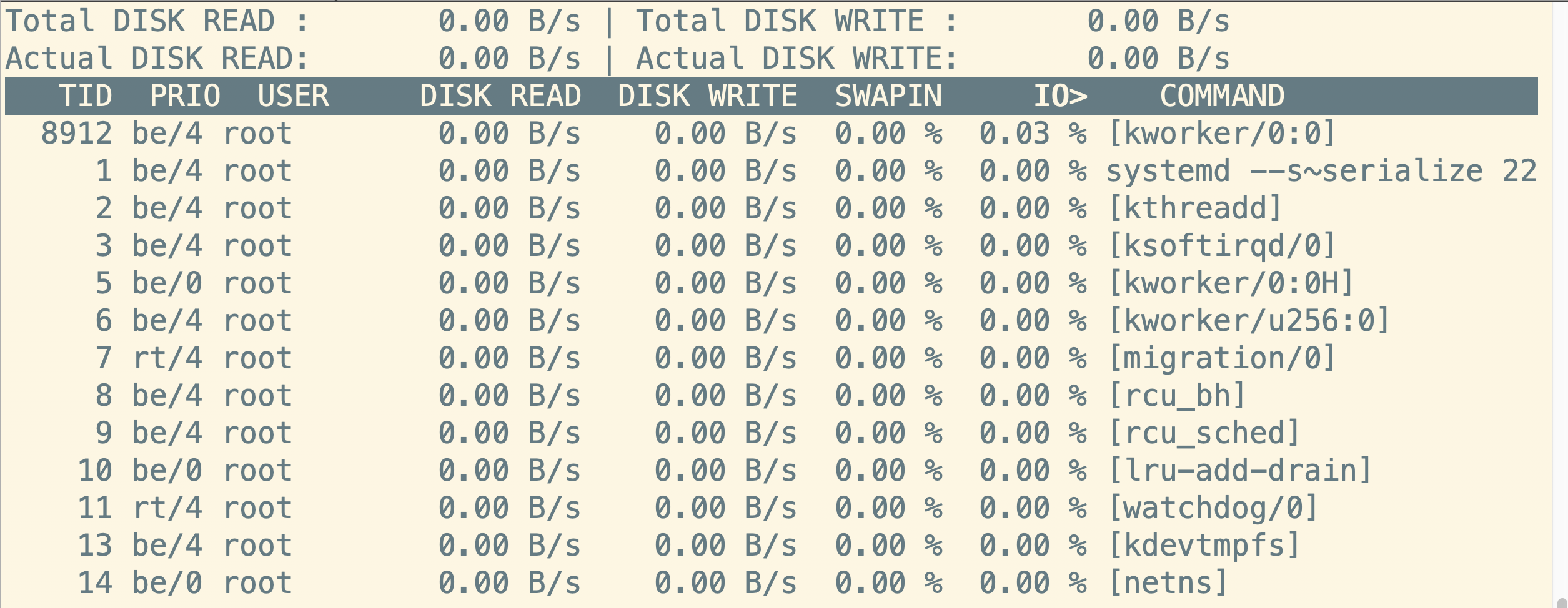
状态解释:
#第一行 磁盘读写的速率总计
Total DISK READ :
Total DISK WRITE :
#第二行 磁盘读写的实际速率
Actual DISK READ:
Actual DISK WRITE:
#第三行 具体的进程速率信息
TID #线程ID,按p切换为进程PID
PRIO #优先级
USER #运行用户
DISK READ #磁盘读的速率
DISK WRITE #磁盘写的速率
SWAPIN #swap交换分区百分比
IO #IO等待百分比
COMMAND #运行的进程
案例演示:
[root@linux opt]# iotop -b -n 1 -a -qqq |head -n 5
1 be/4 root 0.00 B 0.00 B 0.00 % 0.00 % systemd --switched-root --system --deserialize 22
2 be/4 root 0.00 B 0.00 B 0.00 % 0.00 % [kthreadd]
3 be/4 root 0.00 B 0.00 B 0.00 % 0.00 % [ksoftirqd/0]
5 be/0 root 0.00 B 0.00 B 0.00 % 0.00 % [kworker/0:0H]
6 be/4 root 0.00 B 0.00 B 0.00 % 0.00 % [kworker/u256:0]
第5章 网络监控
netstat
netstat 是一个非常有用的网络监控工具,用于显示网络连接、路由表、接口统计等信息。当你运行 netstat 命令,你可以使用不同的选项来显示不同类型的网络数据。下面是一些常见用法的输出字段解释:
常用 netstat 选项
-a:显示所有活动连接和监听端口。-r:显示路由表。-n:显示网络地址和端口号。-t:仅显示TCP连接。-u:仅显示UDP连接。-l:仅列出处于监听状态的套接字。
输出字段的解释
当查看连接 (netstat -nat 或 netstat -nau)
- Proto: 协议类型(如TCP, UDP)。
- Local Address: 本地计算机的IP地址和端口号,格式通常是
IP地址:端口号。如果端口号是*或0.0.0.0,表示监听所有IP地址。 - Foreign Address: 远端计算机的IP地址和端口号,格式同本地地址。
*或0.0.0.0在这里表示对方的地址和端口不固定。 - State: 当前连接的状态。对于TCP连接,常见状态包括:
LISTEN: 套接字在等待进来的连接。ESTABLISHED: 连接已经建立。SYN_SENT: 正在等待匹配的连接请求。SYN_RECV: 初始的同步请求已经收到,等待确认。FIN_WAIT1: 连接被本地应用关闭,等待远端确认。FIN_WAIT2: 远端已经确认连接关闭的请求。TIME_WAIT: 等待足够的时间以确保远端已收到连接终止请求的确认。CLOSE: 没有任何连接状态。CLOSE_WAIT: 远端已关闭连接,本地等待关闭。LAST_ACK: 远端等待原来的关闭请求的确认。
- Recv-Q 和 Send-Q: 接收队列和发送队列的长度(未确认的数据包)。
当查看路由表 (netstat -nr)
- Destination: 目的网络或主机。
- Gateway: 到达目标所需的网关或路由器。
- Genmask: 目的地网络的子网掩码。
- Flags: 路由选项(如 U 表示路由是活跃的,G 表示使用网关,H 表示目的地是一个主机)。
- MSS: 最大段大小,TCP连接中可以使用的最大数据段大小。
- Window: TCP连接的窗口大小。
- irtt: 初始往返时间。
- Iface: 用于该路由的网络接口。
netstat 命令提供的信息对于诊断网络问题和监控系统的网络活动非常有用。通过熟悉 netstat 的不同选项和输出,管理员可以有效地管理和故障排查网络连接。
iftop
命令作用:
实时显示网络流量,类似与top和iotop
常用参数:
-h #帮助说明
-B #以bytes为单位显示
-i #指定网卡
-n #不解析DNS
交互式按键:
b #显示进度条
n #打开或关闭DNS解析名称
t #切换流量显示模式
q #退出
运行结果:
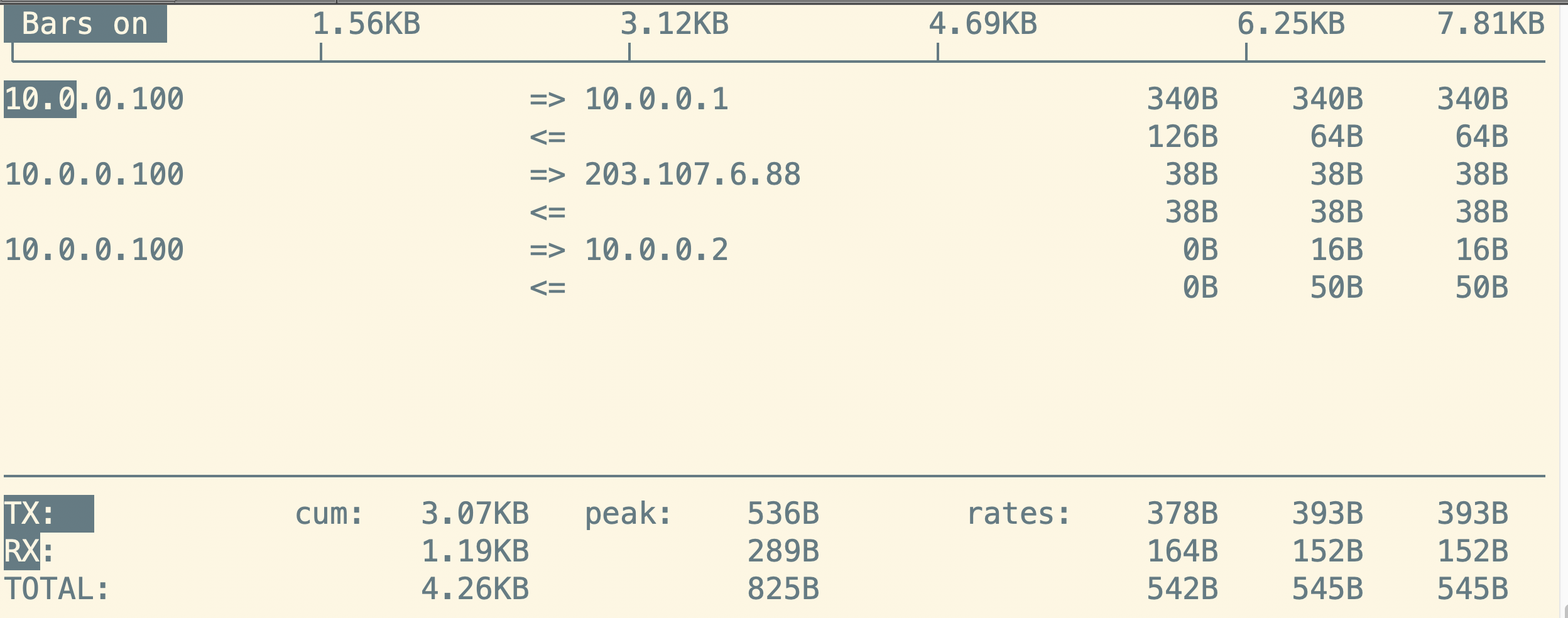
状态解释
TX: 传输流量(Transmit),从本地接口向外发送的总流量。
RX: 接收流量(Receive),接收到的总流量。
TOTAL: 总流量,包括所有传入和传出的数据。
案例演示:
[root@linux ~]# iftop -B -n -i eth0
第x章 系统资源综合监控
vmstat
vmstat(Virtual Memory Statistics)是一个非常实用的命令行工具,用于显示关于系统的虚拟内存、进程、CPU活动等的统计信息。这个工具可以帮助你监测操作系统的性能,并诊断潜在的问题。
vmstat 输出字段的解释
- procs
- r: 等待运行的进程数。
- b: 处于不可中断睡眠状态的进程数。
- memory
- swpd: 使用的虚拟内存量。
- free: 空闲的物理内存量。
- buff: 用作缓冲的内存量。
- cache: 用作缓存的内存量。
- swap
- si: 从磁盘交换到内存的内存量(每秒)。
- so: 从内存交换到磁盘的内存量(每秒)。
- io
- bi: 从块设备接收的块数(每秒)。
- bo: 发送到块设备的块数(每秒)。
- system
- in: 每秒中断次数,包括时钟中断。
- cs: 每秒上下文切换数。
- cpu(以下字段均为CPU时间百分比)
- us: 用户级应用程序使用的CPU时间百分比。
- sy: 系统(内核)级应用程序使用的CPU时间百分比。
- id: 空闲的CPU时间百分比。
- wa: 等待I/O的CPU时间百分比。
mpstat
mpstat 是 Linux 下一个非常有用的命令,用于报告多核 CPU 的使用情况和统计信息。它可以帮助你理解各个 CPU 或核心是如何被使用的,从而对系统的性能进行更细致的分析和调优。
mpstat 输出字段的解释
当你运行 mpstat,它的输出包括以下字段:
- CPU: 这列显示的是 CPU 的标识符。在多核系统中,它会列出所有核心,比如 CPU0、CPU1 等,以及一个总结行 'all',显示所有核心的平均使用情况。
- %usr: 显示了在用户级别(应用程序)花费的 CPU 时间百分比。这不包括通过 nice 调整优先级的时间。
- %nice: 显示了通过 nice 调整优先级的进程使用的 CPU 时间百分比。
- %sys: 显示了在系统(内核)级别花费的 CPU 时间百分比。这包括处理系统调用和内核进程所花费的时间。
- %iowait: 显示 CPU 等待输入输出操作完成的时间百分比。高的 iowait 值通常表明磁盘 I/O 是性能瓶颈。
- %irq: 显示处理硬件中断请求所花费的 CPU 时间百分比。
- %soft: 显示处理软件中断请求所花费的 CPU 时间百分比。
- %steal: 在虚拟化环境中,显示其他虚拟机占用的被“偷走”的 CPU 时间百分比。
- %guest: 显示运行虚拟处理器所花费的 CPU 时间百分比。
- %gnice: 显示运行被 nice 的虚拟处理器所花费的 CPU 时间百分比。
- %idle: 显示 CPU 处于闲置状态的时间百分比。
最佳实践
使用 mpstat 时,可以考虑以下最佳实践来更有效地监控和优化你的系统:
- 定期监控: 定期运行
mpstat可以帮助你跟踪 CPU 使用模式,特别是在系统负载变化大的情况下。
bash
Copy code
mpstat 1 10
这将每秒采集一次数据,连续采集10次。
- 详细监控单个 CPU 或核心: 如果你的系统有多个 CPU 核心,你可以指定核心来观察特定核心的性能。
bash
Copy code
mpstat -P 1 1 10 # 监控 CPU1,每秒一次,总共10次
- 分析 CPU 等待时间: 如果
%iowait值较高,说明你的系统可能存在 I/O 瓶颈。这时,你应该进一步检查磁盘使用情况和优化 I/O 性能。 - 响应虚拟化性能问题: 在虚拟化环境中,
%steal值高表明虚拟 CPU 时间被其他虚拟机占用。这可能需要调整虚拟机的资源配置或迁移到负载较低的物理服务器。 - 检测中断和软件中断: 通过观察
%irq和%soft值,你可以了解系统是如何响应硬件和软件中断的。异常高的值可能需要进一步调查设备驱动程序或相关的配置问题。

dstat
综合的,可以替代vmstat, iostat, netstat,显示详细的系统统计数据。
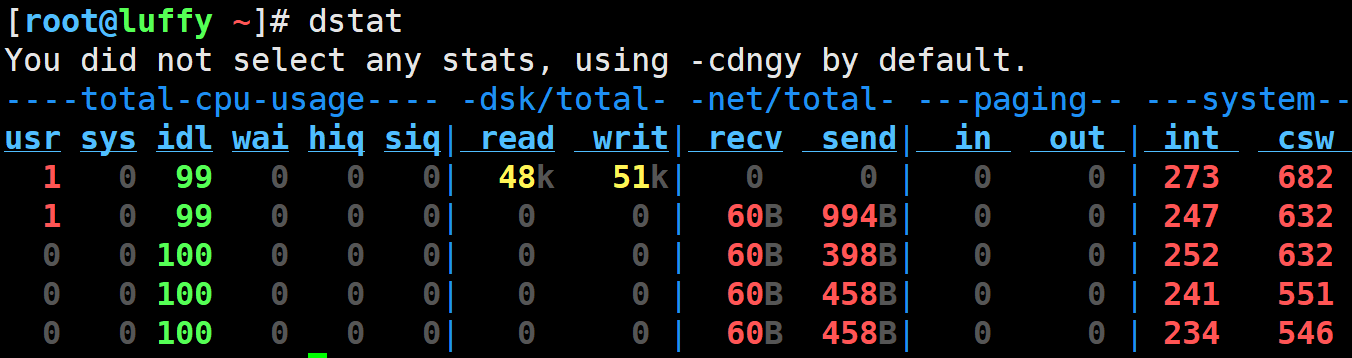
dstat 是一个通用的系统资源统计工具,它提供了多种系统资源的实时数据,可以用来监控系统性能。默认情况下,dstat 使用 -cdngy 选项,表示显示 CPU、磁盘、网络、分页(paging)和系统统计信息。下面是您提到的输出字段的详细解释:
CPU统计 (total-cpu-usage)
- usr: 用户空间占用的CPU百分比(%)。这表示CPU正在执行用户级任务(如应用程序),不包括nice值为负的进程。
- sys: 内核空间占用的CPU百分比(%)。这表示CPU正在执行内核级任务。
- idl: CPU处于空闲状态的时间百分比(%)。没有任何程序请求CPU时间。
- wai: 等待I/O的CPU时间百分比(%)。CPU空闲,但有未完成的I/O请求。
- hiq: 处理硬件中断的时间百分比(%)。
- siq: 处理软件中断的时间百分比(%)。
磁盘统计 (dsk/total)
- read: 读取磁盘的数据量(每秒字节)。显示系统从所有磁盘读取的数据总量。
- writ: 写入磁盘的数据量(每秒字节)。显示系统向所有磁盘写入的数据总量。
网络统计 (net/total)
- recv: 网络接收的数据量(每秒字节)。显示所有网络接口接收的数据总量。
- send: 网络发送的数据量(每秒字节)。显示所有网络接口发送的数据总量。
分页统计 (paging)
- in: 换入的数据量(每秒页面数)。这是指从磁盘读取到内存的页面数量。
- out: 换出的数据量(每秒页面数)。这是指从内存写入到磁盘的页面数量。
系统统计 (system)
- int: 每秒中断的次数。这包括来自硬件设备的中断请求。
- csw: 每秒上下文切换的次数。上下文切换是指CPU从一个进程或线程切换到另一个进程或线程。
通过观察这些统计数据,您可以得到系统当前状态的全面视图,包括CPU的使用情况、磁盘和网络I/O性能、内存分页活动以及系统的响应能力。这些信息对于系统性能调优和问题诊断非常有用。
监控命令整理
| 资源类别 | stat命令 | top命令 |
|---|---|---|
| CPU | mpstat, pidstat, sar | top, htop, atop, nmon |
| 内存 | vmstat, pidstat, sar, | top, htop, atop, nmon |
| 磁盘 | iostat, sar | iotop, atop, nmon |
| 网络 | netstat, sar | iftop, ntop, nmon |
| 进程 | pidstat | top, htop, atop |
| 综合 | vmstat, sar, dstat | top, htop, atop, nmon |
关于面试中常被问道的一些关键词
关键词:CPU负载过高、CPU使用率过高、系统负载过高
CPU使用率过高
CPU使用率是指CPU的利用程度,通常表示为一个百分比,显示了CPU正在执行活动(非空闲)进程的时间比例。当CPU使用率接近或达到100%时,意味着CPU正在全力运行,几乎没有空闲时间。这可能是因为当前有多个进程或线程在积极使用CPU资源。高CPU使用率通常指示CPU在某个时间点被充分利用。
CPU负载过高
CPU负载描述的是请求CPU时间的进程数量。这不仅包括当前正在CPU上执行的进程,还包括等待CPU资源的进程。CPU负载通常通过一定时间内的平均活动进程数来度量,常见的有1分钟、5分钟和15分钟三种平均值。例如,如果一个系统有一个CPU核心,负载为1.0意味着CPU被完全占用;负载超过1.0则表示有进程等待CPU时间,可能会导致性能下降。
系统负载过高
系统负载并不局限于CPU,它涵盖了所有要求系统资源的活动,包括CPU、内存、磁盘I/O等。当提到系统负载过高时,通常指的是系统中的一个或多个资源成为瓶颈,这可能导致整体性能下降。系统负载的增加可能是由于多种原因,如过多的进程、内存不足、磁盘I/O阻塞等。
关系与区别
- 关系:这三个指标都与系统的性能和响应能力有关。CPU使用率高可能导致CPU负载增加,而系统负载高则可能是因为CPU、内存或其他资源的高利用率。
- 区别:CPU使用率仅关注CPU的活动状态;CPU负载更多地反映了等待处理的任务数量;系统负载考虑了所有关键资源的利用情况。
在解决性能问题时,这三个指标各有其重要性。正确地解读这些指标可以帮助系统管理员识别并解决性能瓶颈。例如,如果CPU使用率和CPU负载都很高,那么可能需要优化正在运行的应用或增加更多的CPU资源。如果系统负载高,但CPU使用率不高,则可能需要检查内存使用情况或磁盘I/O性能。
更新: 2024-09-21 20:02:48