13-Linux三剑客-grep
第1章 正则表达式
1.什么是正则表达式
简单地说,正则表达式就是为处理大量的字符串及文本而定义的一套规则和方法。
正则表达式就是把人类想要查的东西,用计算机能识别的语言表达出来的一种规则。
正则表达式仅受三剑客(grep/egrep、sed、awk)命令支持,其他命令无法使用。
2.正则表达式和通配符区别
1.三剑客awk sed grep egrep使用的都是正则,其他都是通配符
2.通配符是针对文件名,正则表达式是针对文件的内容
3.* ? [] 对于通配符来说都能代表任意字符
4.* ? [] 对于正则表达式来说只能代表这些符号前面的字符
3.什么是基本正则和扩展正则
Linux三剑客的正则表达式可分为两类,具体如下。
1.基本正则表达式(BRE,basic regular expression) BRE对应的元字符有“^$.[]*”。·
2.扩展正则表达式(ERE,extended regular expression) ERE在BRE的基础上增加了“()\{\}?+|”等字符。
简单来说,就是扩展正则支持的符号更多,实现的功能更强大。
4.基本正则表达式常用符号
^ 以什么开头,"^luffy" 表示匹配以luffy单词开头的行
$ 以什么结尾,"luffy$",表示匹配以luffy单词结尾的行
^$ 组合符号,表示空行。逻辑解释就是以^开始,以$结尾的行
. 匹配任意且只有一个字符,但是不匹配空行
\ 转义字符,让特殊符号失效,如"\."只表示小数点
* 匹配前一个字符(连续出现)0次或1次以上,注意,当重复0次的时候,表示什么也没有,但是会撇皮所有内容
.* 组合符,匹配所有内容
[abc] 匹配[]内包含的任意一个字符a或b或c
[a-z] 匹配[]内包含a-z任意一个字符
[0-9] 匹配[]内包含0-9的任意一个数字
[^abc] 匹配不包含^后的任意字符a或b或c,这里的^表示对[abc]的取反,与在外面的^意义不同
5.拓展正则表达式常用符号
+ 匹配前1个字符1次或多次
[:/]+ 匹配括号内的 ":" 或 "/" 字符1次或多次
? 匹配前一个字符0次或1次
| 表示或者,即同时过滤多个字符串
() 分组过滤,被括起来的内容表示一个整体,另外()的内容可以被后面的\n引用,n为数字,表示引用第几个括号的内容
\n 引用前面()里的内容,例如(abc)\1 表示匹配abcabc
a\{n,m\} 匹配前一个字符最少n次,最多m次
a\{n,\} 匹配前一个字符最少n次
a\{n\} 匹配前一个字符正好n次
a\{,m\} 匹配前一个字符最多m次
6.正则表达式练习
因为正则表达式的练习离不开三剑客命令,所以下面我们就使用grep命令来练习。
第2章 三剑客命令-grep
1.命令使用
命令作用:
专门用来过滤和搜索文本内容的命令,grep默认只支持基础正则表达式,使用-E参数,或者直接使用egrep命令就可以支持拓展正则了。
常用选项:
-o 只显示匹配到的内容,默认会全部打出来
-w 精确匹配整个单词,默认是贪婪匹配
-n 显示所有匹配的内容的行好
-c 仅统计匹配内容的总行数
-A After 匹配的内容的后多少行
-B Before 匹配的内容的前多少行
-C Context 匹配的内容前后多少行
-E 支持扩展正则
-i 忽略大小写
-f 可以讲匹配模式写进文件里,然后直接指定文件,根据文件里的匹配模式过滤
-color=auto 匹配上的内容高亮显示
2.基础正则表达式练习
2.1 创建测试文本
cat > luffy.txt << EOF
I am oldzhang !
I teach linux.
test
I like swimming, football, basketball, video games
I like ChaShao TaiQiu
my blog is https://www.cnblogs.com/alaska/
my site is https://www.jianshu.com/u/ee1c7fcea5b0
my-qq is 526195417.
my_phone is 15321312624.
EOF
2.2 ^ 查找以什么开头的行

2.3 $ 查找以什么结尾的行

2.4 ^$ 查找和排除空行
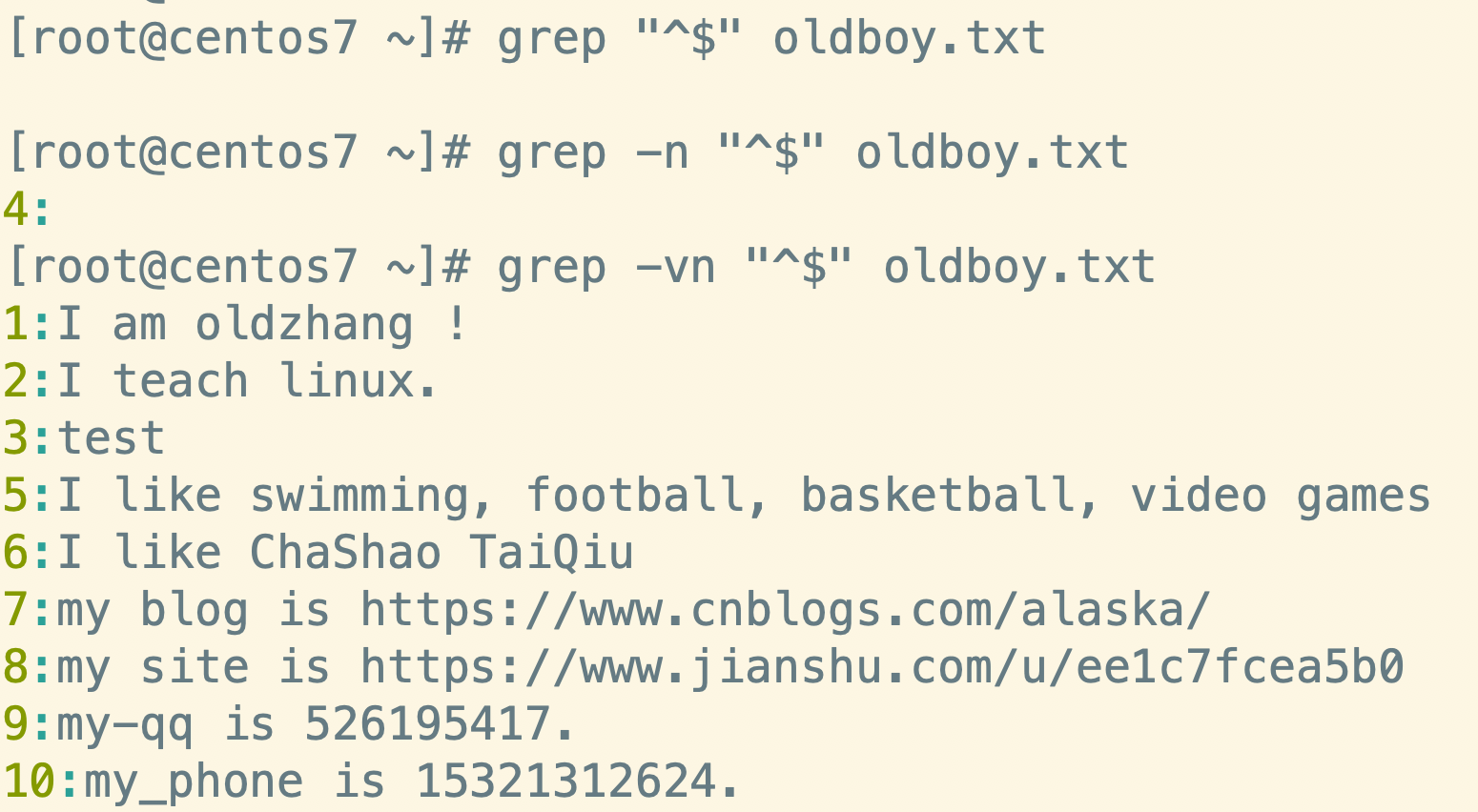
2.5 . 任意一个字符 不会匹配空行 包含空格
- 默认贪婪匹配,会匹配所有的内容:
grep . luffy.txt
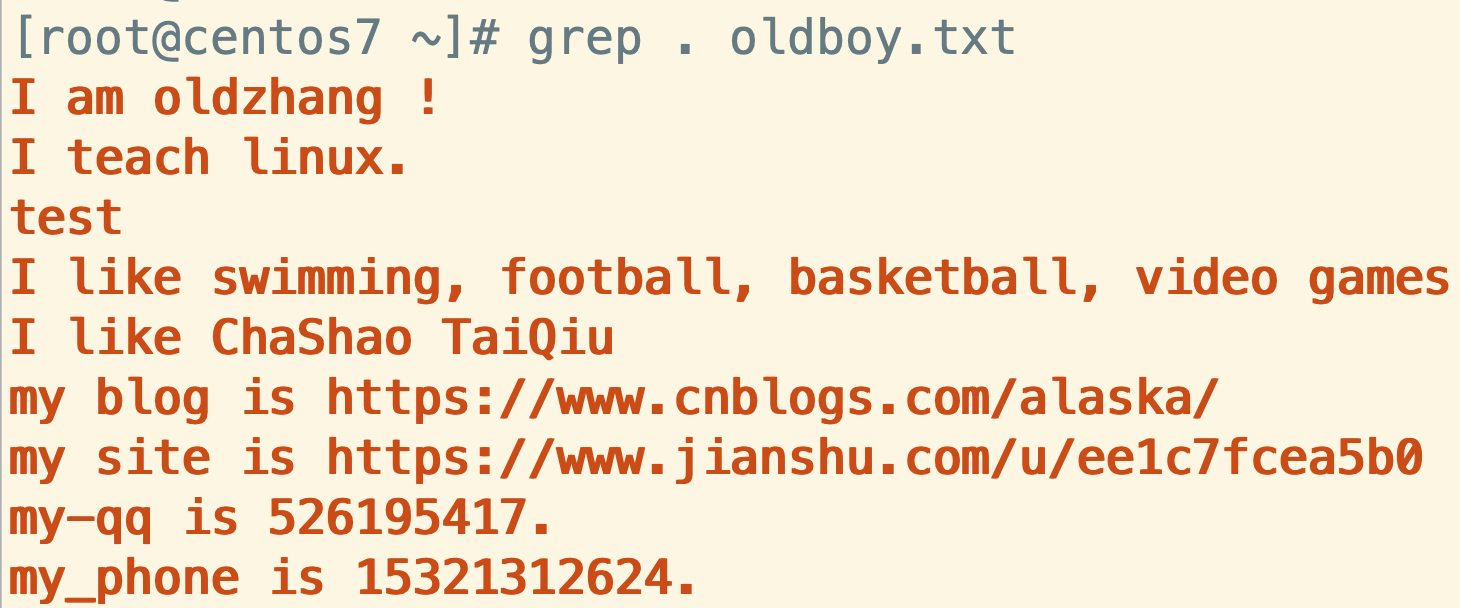
默认的贪婪匹配会把所有内容都匹配完后一起输出,如果我们想看每一次的匹配内容可以使用-o参数
grep . luffy.txt -o

- 匹配一个任意字母的单词,默认会打印匹配到的行
grep "li.e" luffy.txt

- 匹配多个任意字母的单词
grep "li.." luffy.txt

2.6 \ 转义特殊字符
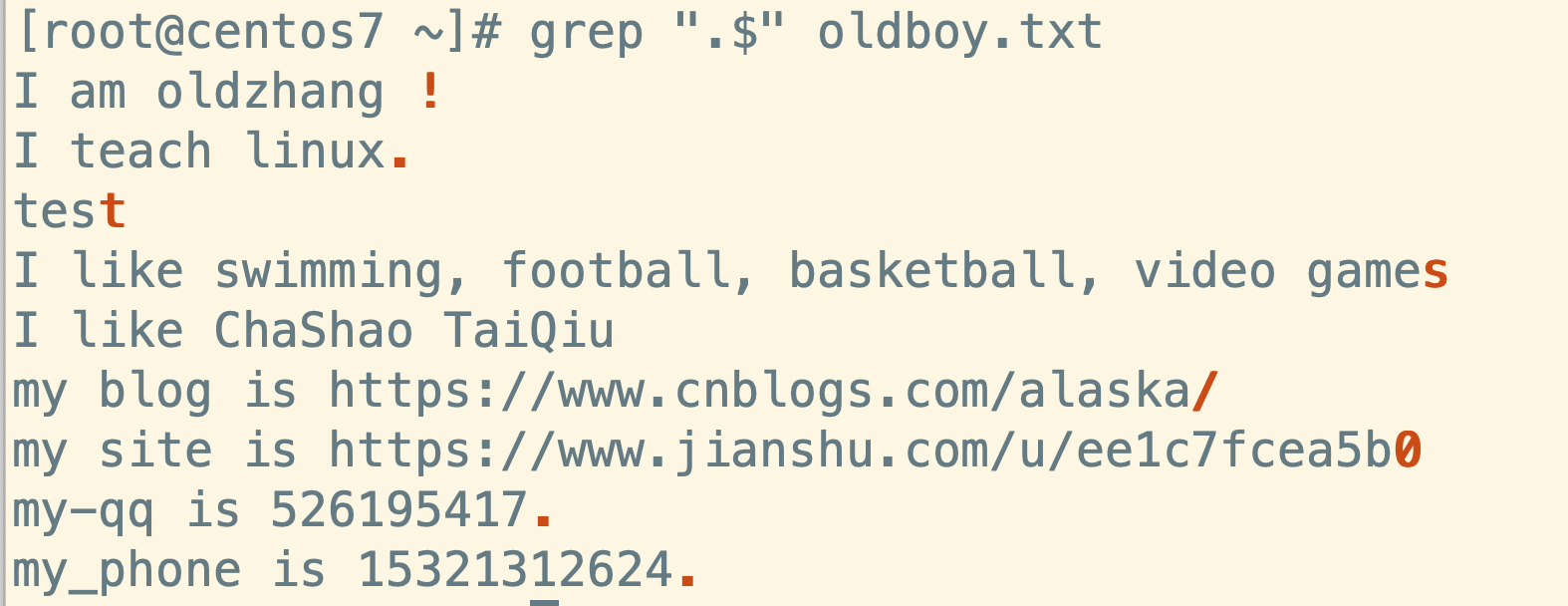
假如有需求:查找所有以 . 结尾的内容
如果不转义特殊字符的话,. 这个符号会被认为是正则表达式
grep ".$" luffy.txt
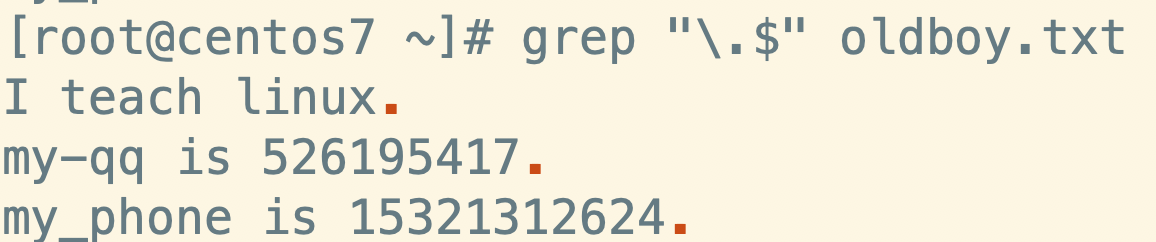
如果我们想过滤的是.的话,需要使用\将正则表达式符号转换为普通的符号
grep "\.$" luffy.txt
2.7 [ ]匹配字符
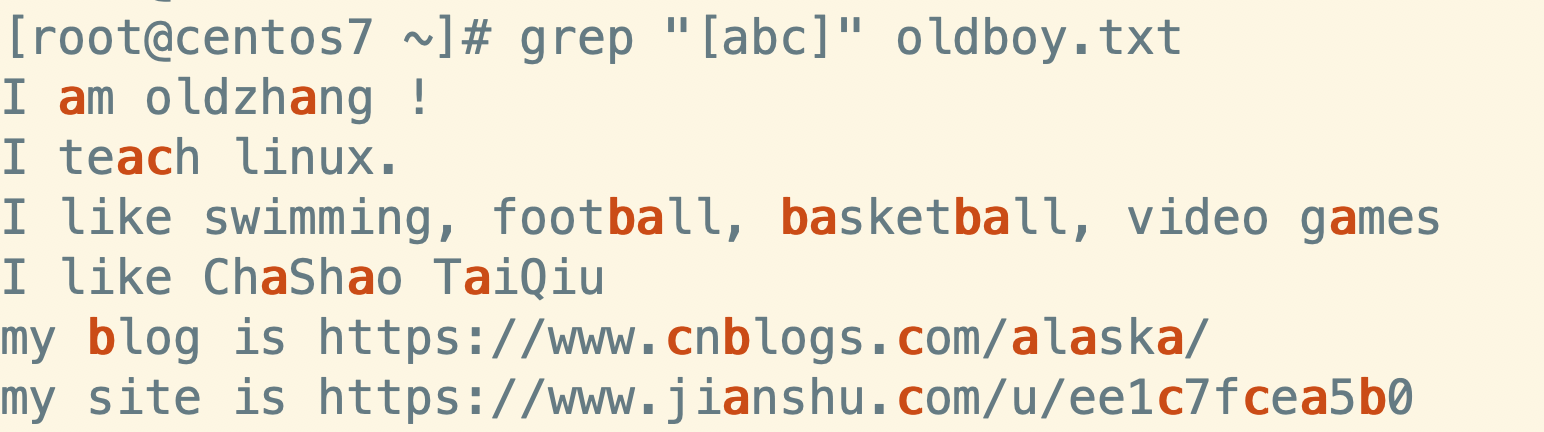
- 匹配包含abc任意字符串
grep "[abc]" luffy.txt
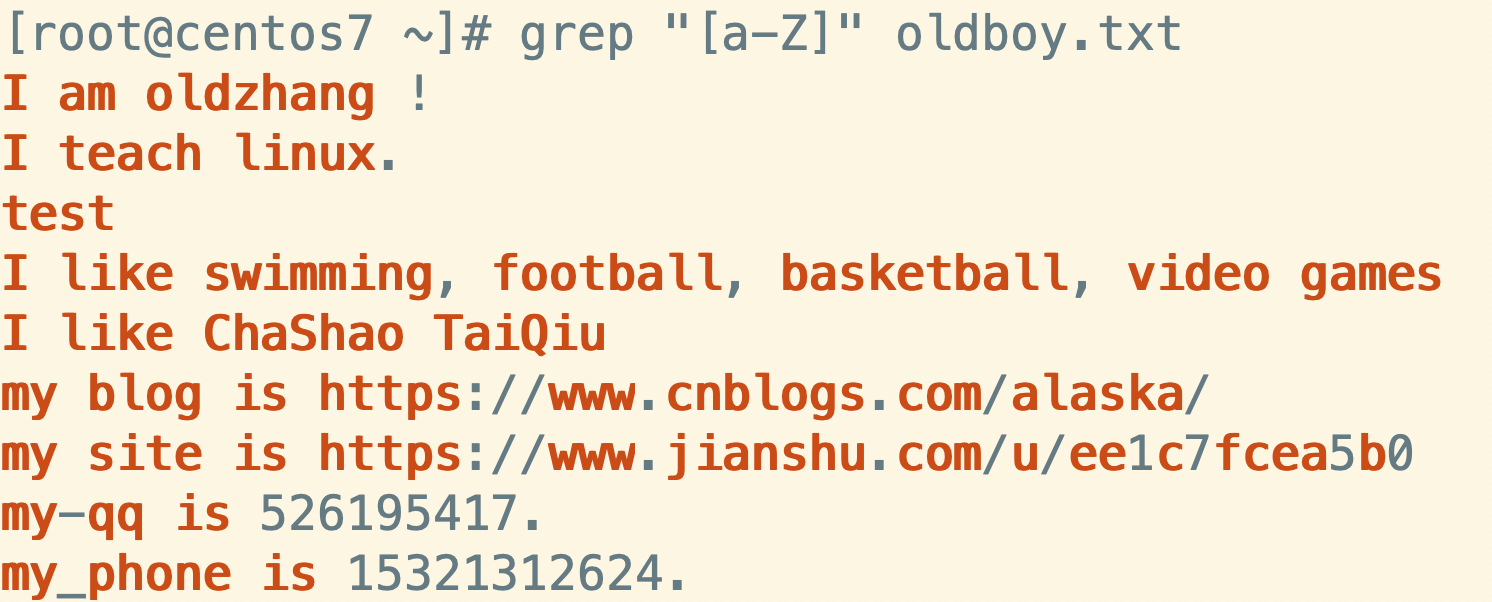
- 匹配a-Z的任意字符
grep "[a-Z]" luffy.txt
- 匹配0-9的字符串
grep "[0-9]" luffy.txt

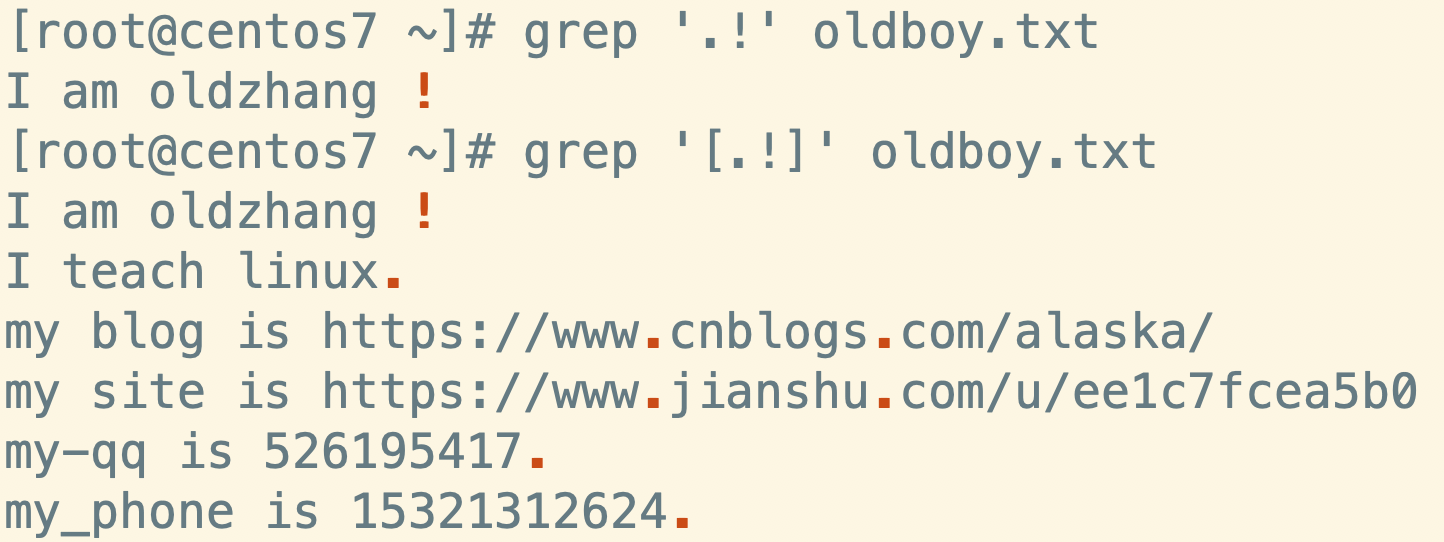
- [ ]匹配特殊字符,[ ]里大部分字符没有特殊含义,写什么就查找什么
查找包含 ! 和 . 的内容
grep '.!' luffy.txt
grep '[.!]' luffy.txt
[^ ] 取反,在[ ]里面^变成了取反的意思
排除以my开头的行
grep '^[^my]' luffy.txt

2.8 -i 忽略大小写
默认大小写敏感
grep -Ew 'c[a-Z]+' luffy.txt

使用-i参数忽略大小写
grep -Eiw 'c[a-Z]+' luffy.txt

3.拓展正则练习
3.1 { n } 匹配前一个字符最多n次
匹配手机号而不是QQ号
grep -E '[0-9]\{11\}' luffy.txt

3.3 { n,m } 匹配前一个字符最少n次,最多m次
grep -E 'w\{1,2\}' luffy.txt

3.4 ()分组引用
查找出所有单词中出现字母连续的行,比如www,http
grep -E '([a-z])\1' luffy.txt

查找出同一个字母连续3次的行,比如www
grep -E '([a-z])\1\{2\}' luffy.txt

3.4 +和[]和()组合 匹配多次
从日志里提取网址
grep -oE '[a-z]+\.[a-Z]+\.[a-Z]+' luffy.txt
grep -oE '([a-z]+\.)\{1,3\}[a-Z]+' luffy.txt

进阶:提取完整的链接地址
grep -oE '[a-Z]+://([a-z]+\.)\{1,3\}[a-Z]+(/[a-Z0-9]+)+' luffy.txt

4.工作需求
4.1 排除配置文件所有注释的行以及空行--必会
#1.原始内容
[root@centos7 yum.repos.d]# cat /etc/nginx/conf.d/default.conf
server \{
listen 80;
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / \{
root /usr/share/nginx/html;
index index.html index.htm;
\}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html \{
root /usr/share/nginx/html;
\}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ \{
# proxy_pass http://127.0.0.1;
#\}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ \{
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#\}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht \{
# deny all;
#\}
\}
#2.排除所有注释的行
[root@centos7 yum.repos.d]# grep -v '#' /etc/nginx/conf.d/default.conf
server \{
listen 80;
server_name localhost;
location / \{
root /usr/share/nginx/html;
index index.html index.htm;
\}
error_page 500 502 503 504 /50x.html;
location = /50x.html \{
root /usr/share/nginx/html;
\}
\}
#3.排除注释的行以及空行
[root@centos7 yum.repos.d]# egrep -v '#|^$' /etc/nginx/conf.d/default.conf
server \{
listen 80;
server_name localhost;
location / \{
root /usr/share/nginx/html;
index index.html index.htm;
\}
error_page 500 502 503 504 /50x.html;
location = /50x.html \{
root /usr/share/nginx/html;
\}
\}
4.2 查找某个进程是否存在-秘技
#1.默认查找进程并过滤的时候grep会多一条高亮显示的进程
[root@centos7 ~]# ps aux|grep nginx
root 7907 0.0 0.0 112724 988 pts/0 R+ 20:01 0:00 grep --color=auto nginx
[root@centos7 ~]# ps aux|grep nginx|grep -v grep
[root@centos7 ~]#
#2.思考为什么添加了[]就不会出现高亮显示的进程信息了?
[root@centos7 ~]# ps aux|grep [n]ginx
[root@centos7 ~]# ps aux|grep [n]ginx|wc -l
0
[root@centos7 ~]#
4.3 查看sda磁盘的使用率
[root@centos7 ~]# df |grep '^/dev/sda'|grep -oE '[0-9]+%'|grep -oE '[0-9]+'
14
4.4 取出eth0网卡的IP地址
[root@centos7 ~]# ifconfig eth0|grep 'inet '|grep -oE '[0-9]\{1,3\}.[0-9]\{1,3\}.[0-9]\{1,3\}.[0-9]\{1,3\}.'|head -1
10.0.0.100
[root@centos7 ~]# ifconfig eth0|grep 'inet '|grep -oE '([0-9]\{1,3\}.)\{,4\}'|head -1
10.0.0.100
[root@centos7 ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0|grep 'IPADDR'|grep -oE '([0-9]\{1,3\}.)\{,4\}'
10.0.0.100
4.5 统计/etc/passwd所有shell为nologin的行并只显示用户名
[root@centos7 ~]# grep 'nologin' /etc/passwd|grep -oE '^[a-Z]+:'|grep -oE '[a-Z]+'
bin
daemon
adm
lp
mail
operator
games
ftp
nobody
dbus
polkitd
sshd
postfix
chrony
ntp
4.6 查找/dev/sda的UUID
[root@centos7 ~]# blkid /dev/sda1|grep -oE '[a-Z0-9]+\-[a-Z0-9]+\-[a-Z0-9]+\-[a-Z0-9]+\-[a-Z0-9]+'
6c86cd7e-9ff1-4398-af1b-b69ac8a6cbfb
[root@centos7 ~]# blkid /dev/sda1|grep -oE '([a-Z0-9]+\-)\{1,4\}[a-Z0-9]+'
6c86cd7e-9ff1-4398-af1b-b69ac8a6cbfb
4.7 统计TCP连接状态
[root@centos7 ~]# ss -ant|grep -v 'State'|grep -oE [A-Z]+|uniq -c|sort -n
1 ESTAB
2 LISTEN
2 LISTEN
第3章 三剑客命令-sed
1.sed介绍
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器.
sed就像车间的流水线一样,需要处理的字符就是流水线上的原材料,经过sed处理后,就变成了货物。
sed的应用场景主要如下:
1.查找和过滤文件内容
2.替换文件内容
3.脚本里可以用来检查输入是否纯英文或者纯数字
2.sed命令使用
命令作用:
sed [options] [sed-commands] [input-file]
sed [选项] [sed命令] [输入文件]
执行过程:
1.sed从文件或管道读取一行,处理一行,输出一行
2.再读取一行.再处理一行.在输出一行
常用选项:
-n 取消默认的sed软件的输出,常与sed命令的p连用
-e 一行命令语句可以执行多条sed命令
-r 使用正则拓展表达式,默认情况sed只识别基本正则表达式
-i 直接修改文件内容,而不是输出终端,如果不使用-i选项sed软件只是修改在内存中的数据,并不影响磁盘上的文件
常用命令:
a 追加,在指定行后添加一行或多行文本
c 取代指定的行
d 删除指定的行
i 插入,在指定的行前添加一行或多行文本
p 打印内容,通常和-n一起使用
s 取代 s#要替换的内容#替换的内容#g
特殊符号:
! 对指定行以外的所有行应用命令
= 打印当前行号
; 实现一行命令语句可以执行多条sed命令
3.sed练习-查找
sed查找主要是用到-n和p的组合,-n用来取消默认输出,p表示只显示匹配的行。
测试文本
cat > luffy.txt << EOF
I am oldzhang !
I teach linux.
testtt0aaaasssabcc788ayyytt
#I like swimming, football, basketball, video games
I like ChaShao TaiQiu
#my blog is https://www.cnblogs.com/alaska/
my site is https://www.jianshu.com/u/ee1c7fcea5b0
#my-qq is 526195417.
my_phone is 1532000233111112.
EOF
查找单行
查找第2行
[root@centos7 ~]# sed -n '2p' luffy.txt
I teach linux.
查找多行
查询第2行到第3行
[root@centos7 ~]# sed -n '2,3p' luffy.txt
I teach linux.
testtt0aaaasssabcc788ayyytt
关键词查找
按字包含Cha关键词的行
[root@centos7 ~]# sed -n '/Cha/p' luffy.txt
I like ChaShao TaiQiu
关键词查找
查找以I开头的行
[root@centos7 ~]# sed -n '/^I/p' luffy.txt
I am oldzhang !
I teach linux.
I like ChaShao TaiQiu
按关键词范围查找
查找oldzhang到Cha中间所有的行
[root@centos7 ~]# sed -n '/oldzhang/,/Cha/p' luffy.txt
I am oldzhang !
I teach linux.
testtt0aaaasssabcc788ayyytt
#I like swimming, football, basketball, video games
I like ChaShao TaiQiu
查找第3行到Cha关键词的行
[root@centos7 ~]# sed -n '3,/Cha/p' luffy.txt
testtt0aaaasssabcc788ayyytt
#I like swimming, football, basketball, video games
I like ChaShao TaiQiu
查找包含ball和linux的行,需要用到扩展正则
[root@centos7 ~]# sed -rn '/ball|linux/p' luffy.txt
I teach linux.
#I like swimming, football, basketball, video games
4.sed练习-增加
增加使用的是a与i命令,分别为关键行前添加或者后面添加
单行增加
在第2行后面新添加一行 good good study day day up
[root@centos7 ~]# sed '2a good good study day day up' luffy.txt |head -4
I am oldzhang !
I teach linux.
good good study day day up
testtt0aaaasssabcc788ayyytt
在第2行前面新添加一行 good good study day day up
[root@centos7 ~]# sed '2i good good study day day up' luffy.txt |head -4
I am oldzhang !
good good study day day up
I teach linux.
testtt0aaaasssabcc788ayyytt
多行增加
在第2行后面新添加两行文本 good good study day day up; you can you up
[root@centos7 ~]# sed '2a good good study day day up\nyou can you up' luffy.txt |head -5
I am oldzhang !
I teach linux.
good good study day day up
you can you up
testtt0aaaasssabcc788ayyytt
在3行前面添加一行aaaaaaaaaaa
[root@centos7 ~]# sed '3i aaaaaaaaaaa' luffy.txt |head -4
I am oldzhang !
I teach linux.
aaaaaaaaaaa
testtt0aaaasssabcc788ayyytt
5.sed练习-替换
替换说明
sed的替换功能非常强大,也是使用sed最多的用途。
默认sed替换并不会真正的修改文件,如果想把修改的内容写入到文件里,需要添加-i参数
命令语法:
sed '[地址范围|模式范围] s#[被替换的关键词]#[需要替换成的关键词]#[替换标志]' [输入文件]
命令解释:
1.[地址范围|模式范围]:可选选项,如果没有指定,sed软件将在所有行上进行替换。
2."s" 即执行替换命令substitute
3.被替换的字符串,可以是一个正则表达式
4.替换后的字符串,只能是一个具体的内容
5.替换标志:可选选项
- 全局标志g
- 数字标志(1,2,3...)
- 打印标志p
- 写标志w
- 忽略大小写标志i
- 执行命令标志e
根据需要可以把一个或多个替代标志组合起来使用。
测试文本
cat > person.txt <<EOF
101,Zhangya,CEO
102,BanZhang,CTO
103,CKman,COO
104,Mr.Sheng,UFO
105,GuanRu,CXO
EOF
指定关键词替换
将CXO替换为XO
#1.直接关键词替换
[root@centos7 ~]# sed 's#CXO#XO#g' person.txt
101,Zhangya,CEO
102,BanZhang,CTO
103,CKman,COO
104,Mr.Sheng,UFO
105,GuanRu,XO
#2.如果只想显示被替换的行,可以使用-n结合p一起使用
[root@centos7 ~]# sed -n 's#CXO#XO#gp' person.txt
105,GuanRu,XO
将所有的a替换为A
[root@centos7 ~]# sed 's#a#A#g' person.txt
101,ZhAngyA,CEO
102,BAnZhAng,CTO
103,CKmAn,COO
104,Mr.Sheng,UFO
105,GuAnRu,CXO
只将第一次匹配上的a替换为A
[root@centos7 ~]# sed 's#a#A#' person.txt
101,ZhAngya,CEO
102,BAnZhang,CTO
103,CKmAn,COO
104,Mr.Sheng,UFO
105,GuAnRu,CXO
只将第二次匹配上的a替换为A
[root@centos7 ~]# sed 's#a#A#2g' person.txt
101,ZhangyA,CEO
102,BanZhAng,CTO
103,CKman,COO
104,Mr.Sheng,UFO
105,GuanRu,CXO
忽略大小写替换 将e和E替换为F
[root@centos7 ~]# sed -r 's#e#F#gi' person.txt
101,Zhangya,CFO
102,BanZhang,CTO
103,CKman,COO
104,Mr.ShFng,UFO
105,GuanRu,CXO
指定行进行替换
将第1行文本替换为200,DongLai,CEO
#1.第一种方法,使用s###g替换
[root@centos7 ~]# sed '1s#.*#200,DongLai,CEO#g' person.txt
200,DongLai,CEO
102,BanZhang,CTO
103,CKman,COO
104,Mr.Sheng,UFO
105,GuanRu,CXO
#2.第二种方法,直接替换指定行内容
[root@centos7 ~]# sed '1c 200,DongLai,CEO' person.txt
200,DongLai,CEO
102,BanZhang,CTO
103,CKman,COO
104,Mr.Sheng,UFO
105,GuanRu,CXO
指定关键词分组替换
CEO和数字替换位置
[root@centos7 ~]# sed -r 's#(.*),(.*),(.*)#\3,\2,\1#g' person.txt
CEO,Zhangya,101
CTO,BanZhang,102
COO,CKman,103
UFO,Mr.Sheng,104
CXO,GuanRu,105
将中间的名字去掉,变成格式:101,CEO
[root@centos7 ~]# sed -r 's#(.*),.*,(.*)#\1,\2#g' person.txt
101,CEO
102,CTO
103,COO
104,UFO
105,CXO
将第一个逗号替换为 - 第二个逗号替换为 _ 举例:101-DongLai_CEO
#1.第一种方法:分组替换
[root@centos7 ~]# sed -r 's#(.*)(,)(.*)(,)(.*)#\1-\3_\5#g' person.txt
101-Zhangya_CEO
102-BanZhang_CTO
103-CKman_COO
104-Mr.Sheng_UFO
105-GuanRu_CXO
#2.第二种方法:命令拼接
[root@centos7 ~]# sed 's#,#-#' person.txt|sed 's#,#_#g'
101-Zhangya_CEO
102-BanZhang_CTO
103-CKman_COO
104-Mr.Sheng_UFO
105-GuanRu_CXO
6.sed练习-删除
删除指定的行
删除第2行的内容
[root@centos7 ~]# sed '2d' person.txt
101,Zhangya,CEO
103,CKman,COO
104,Mr.Sheng,UFO
105,GuanRu,CXO
删除多行
删除第2和第5行
[root@centos7 ~]# sed '2d;5d' person.txt
101,Zhangya,CEO
103,CKman,COO
104,Mr.Sheng,UFO
删除第2行到第4行
[root@centos7 ~]# sed '2,4d' person.txt
101,Zhangya,CEO
105,GuanRu,CXO
使用步长删除 隔几行删除,本行也算一行
1~2,表示删除从第一行开始,隔一行删一行
[root@centos7 ~]# sed '1~2d' person.txt
102,BanZhang,CTO
104,Mr.Sheng,UFO
删除指定行之后的N行
[root@centos7 ~]# sed '1,+2d' person.txt
104,Mr.Sheng,UFO
105,GuanRu,CXO
取反删除 只保留第1和第2行
[root@centos7 ~]# sed '1,2!d' person.txt
101,Zhangya,CEO
102,BanZhang,CTO
删除关键词的行
删除包含关键词的行
[root@centos7 ~]# sed '/UFO/d' person.txt
101,Zhangya,CEO
102,BanZhang,CTO
103,CKman,COO
105,GuanRu,CXO
正则表达式删除 删除名字里包含两个大写字母的行 比如BanZhang
[root@centos7 ~]# sed -r '/.*[A-Z]+[a-z]+[A-Z]+.*/d' person.txt
101,Zhangya,CEO
103,CKman,COO
104,Mr.Sheng,UFO
删除第一个关键词与第二个关键词之间所有的行
[root@centos7 ~]# sed '/CTO/,/UFO/d' person.txt
101,Zhangya,CEO
105,GuanRu,CXO
其他替换标志
替换标志 含义
\l 在替换字符中shiyong\l标志时,他会把紧跟其后面的1个字符当做小写字符来处理
\L 在替换字符中shiyong\L标志时,他会把后面所有的字符都当作小写字符来处理
\u 在替换字符中使用\u标志时,他会把紧其后面的1个字符当作大写字符来处理
\U 在替换字符中使用\U标志时,他会把后面所有的字符都当作大写字符来处理。
\E 需要\U或\L一起使用,他将关闭\U或\L的功能
7. 生产实战
提取IP地址 尽可能多的方法
ifconfig eth0|sed -rn 's#.*t (.*) n.*#\1#p'
cat /etc/sysconfig/network-scripts/ifcfg-eth0|sed -nr '/IPADDR/s#.*=(.*)#\1#p'
修改IP地址 将网卡配置文件里ip地址修改为192.168.1.1
cp /etc/sysconfig/network-scripts/ifcfg-eth0 ifcfg-eth0
sed -r '/IPADDR/s#IPADDR=(.*)#IPADDR=192.168.1.1#g' ifcfg-eth0
sed -r '/IPADDR/c IPADDR=192.168.1.1' ifcfg-eth0
替换nginx配置文件运行用户为www
cp /etc/nginx/nginx.conf .
sed -rn 's#user nginx#user www#p' nginx.conf
sed -rn '/^user/c user www;' nginx.conf
sed -rn 's#user .*;#user www;#p' nginx.conf
将/etc/passwd 第一列取出来
sed -r 's#(^[a-Z0-9-]+).*#\1#' /etc/passwd
sed 's#:.*##g' /etc/passwd
sed 's#:x:.*$##g' /etc/passwd
sed -r 's#(.):.*$#\1#g' /etc/passwd
sed -r 's#(^[^:]+).*$#\1#g' /etc/passwd
sed -r 's#(^.*):x.*$#\1#g' /etc/passwd
sed -r 's#(^[a-zA-Z0-9#-]+).*$#\1#g' /etc/passwd
将/etc/passwd 用户名列,UID列和GID列取出来
sed -r 's#^(.*):.*:(.*):(.*):.*:.*:.*#\1:\2:\3#g' /etc/passwd
将/etc/passwd 第一列和最后一列位置调换
sed -r 's#(^[a-zA-Z0-9#-]+)(:.*:)(.*$)#\3\2\1#g' /etc/passwd
sed -r 's#(^[^:]+)(:.*:)(.*$)#\3\2\1#g' /etc/passwd
批量重命名文件
touch stu_102999_\{1..5\}_finished.jpg
ls|sed -r 's#(.*)_(.*)_(.*)_(.*)(\..*)#\1_\2_\3\5#g'
ls|sed -r 's#(.*)_(.*)_(.*)_(.*)(\..*)#mv & \1_\2_\3\5#g'
ls|sed -r 's#(.*)_(.*)_(.*)_(.*)(\..*)#mv & \1_\2_\3\5#g'|bash
ls *.jpg|sed -r 's#(^.*)_finished.*$#mv & \1.jpg#'
ls stu*|xargs -n1|sed -r "s#(^.*[1-9]).*(.jpg)#mv & \1\2#g"
ls|awk -F "_finished" '\\{print "mv",$0,$1$2\\}'
rename "_finished" "" *.jpg
更改文件同时备份
[root@centos7 ~]# sed -i.bak 's#CEO#CCO#g' person.txt
[root@centos7 ~]# ll person.txt*
-rw-r--r-- 1 root root 79 4月 15 08:14 person.txt
-rw-r--r-- 1 root root 79 4月 14 19:43 person.txt.bak
删除阿里源里包含aliyunc的行
#配置国内yum基础源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
#配置国内yum拓展源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
#删除阿里源里的内网链接
sed -i '/aliyuncs/d' /etc/yum.repos.d/*.repo
从日志里取IP地址
8.sed的坑
乱放p的坑
#号的坑
第4章 三剑客命令-awk
1.awk介绍
2.awk命令格式
命令作用:
命令格式:
awk [options] '[pattern \\{action\\}]'
参数选项 匹配模式 执行动作
awk 带什么家伙 '找谁 \\{干啥\\}' file
常用选项:
-F 指定分隔符,如果是多个,可以使用[]
匹配模式:
// 正则表达式匹配
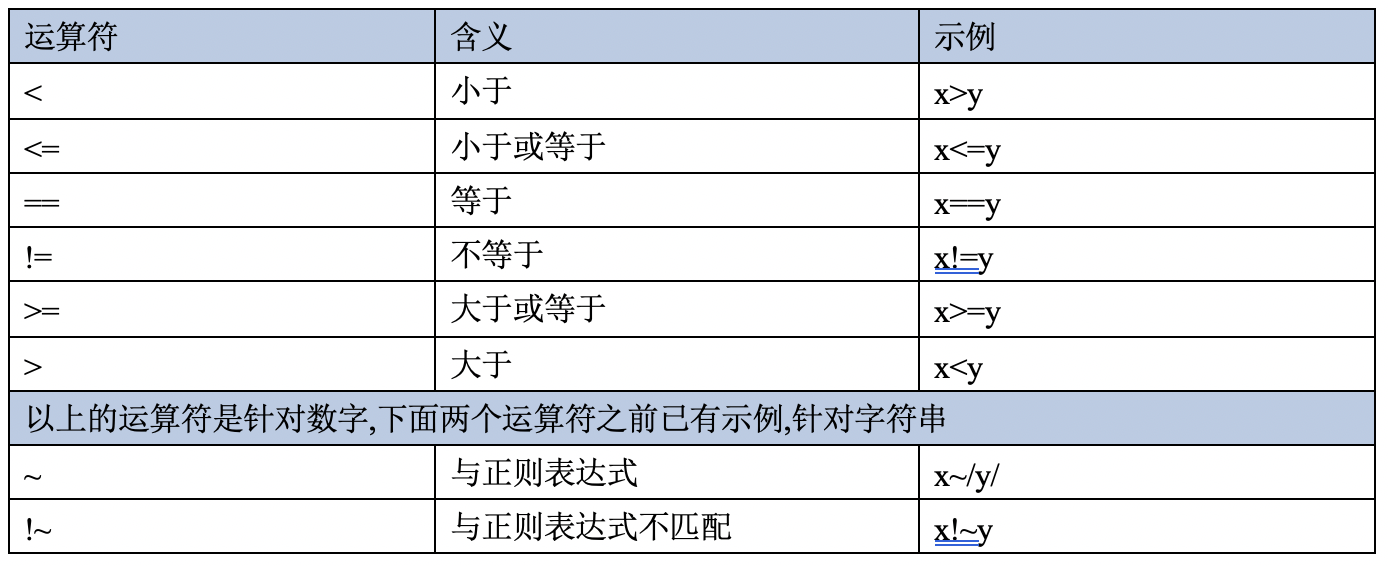
<>= 比较表达式匹配
n,m 范围匹配
执行动作:
print 执行输出动作
3.内置变量介绍
NR 控制匹配的行号
RS
FS 默认分隔符
OFS 默认输出分隔符
$0 表示所有的列
$N 表示第N列
$NF 表示最后一列
4.awk工作原理
5.awk小试身手
4.2 按需求输出列
测试样本:
cat > person.txt << EOF
101,Zhangya:CEO-12000
102,BanZhang:CTO-15000
103,CKman:COO-18000
104,Mr.Sheng:COO-2x000
105,GuanRu:CXO-13000
EOF
5.1 比较匹配模式
5.2 正则匹配模式
5.3 范围匹配模式
7.awk数组
7.1 数组介绍
7.2 数组演示
8.综合练习题
取常用服务端口号
统计IP地址访问排名前10的IP
统计域名访问排名前10的IP
指定IP访问了多少次
指定的
更新: 2024-10-10 20:09:31