第6章 Grafana
grafana介绍
安装部署
cat > grafana.yml << 'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: prom
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
volumes:
- name: storage
hostPath:
path: /data/k8s/grafana/
nodeSelector:
kubernetes.io/hostname: node2
securityContext:
runAsUser: 0
containers:
- name: grafana
image: grafana/grafana:7.4.3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
resources:
limits:
cpu: 150m
memory: 512Mi
requests:
cpu: 150m
memory: 512Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: storage
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: prom
spec:
ports:
- port: 3000
selector:
app: grafana
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana
namespace: prom
labels:
app: grafana
spec:
ingressClassName: nginx
rules:
- host: grafana.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: grafana
port:
number: 3000
EOF
应用资源配置:
[root@node1 prom]# kubectl apply -f grafana.yml
deployment.apps/grafana created
service/grafana created
ingress.networking.k8s.io/prometheus configured
访问测试:
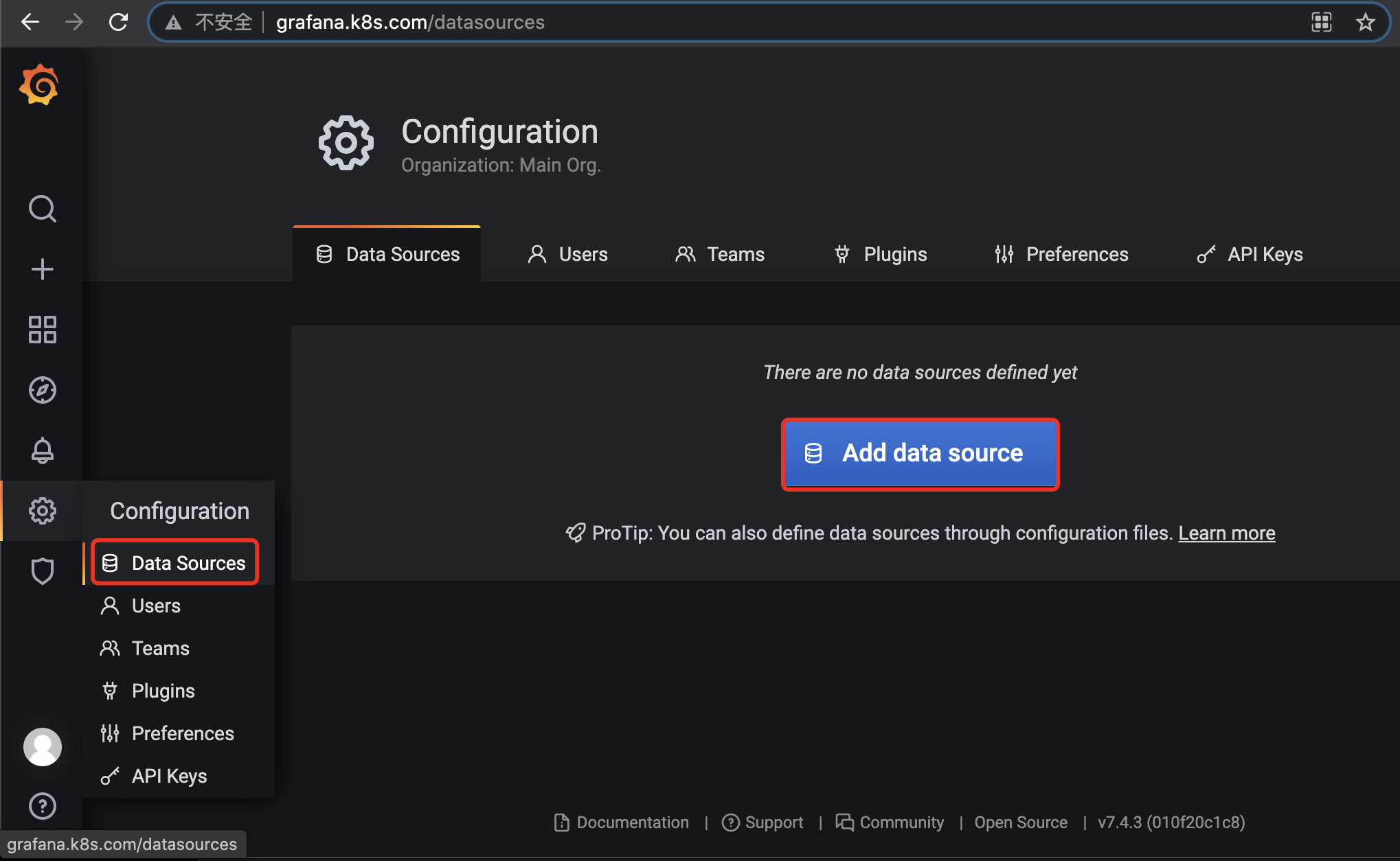
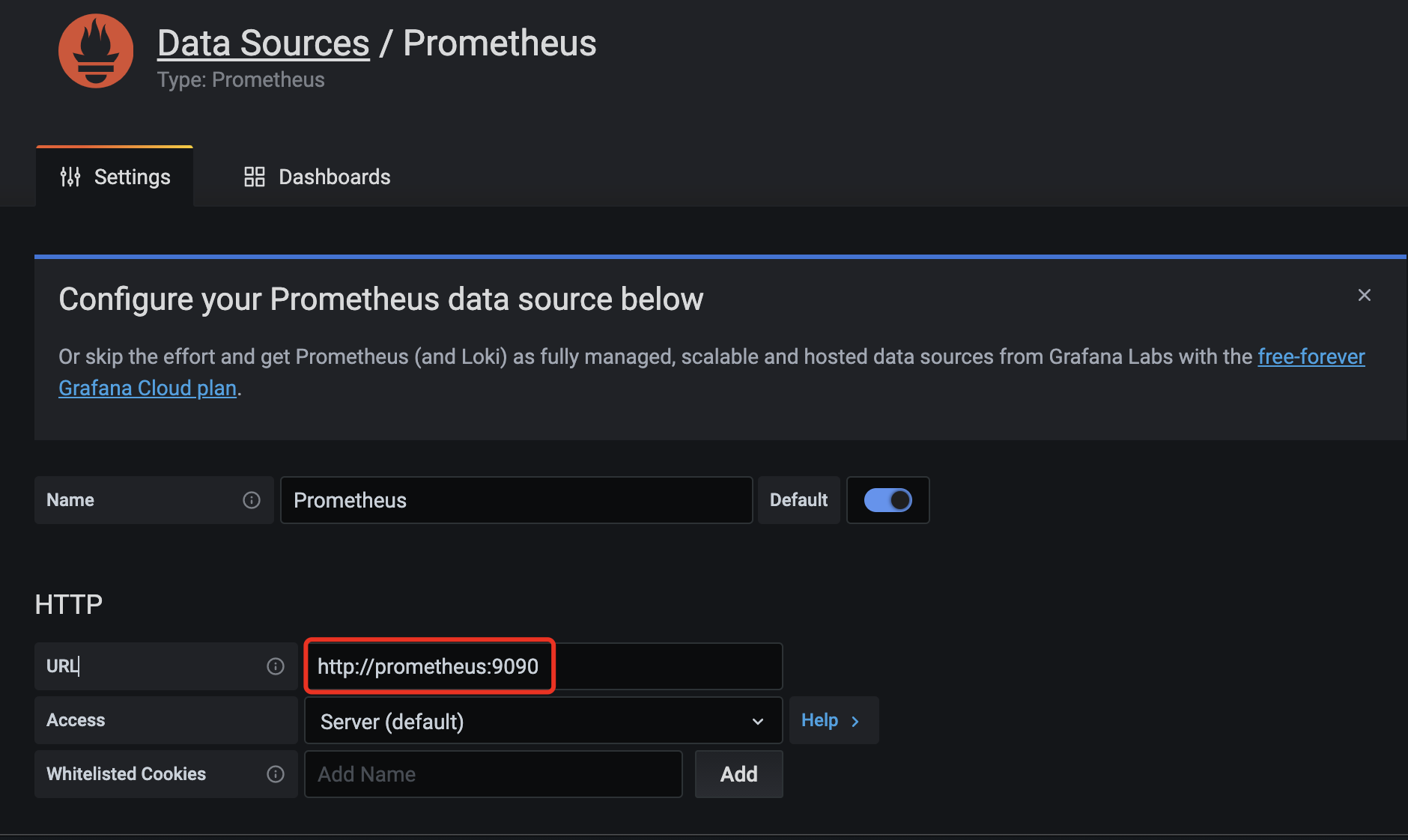
添加数据源

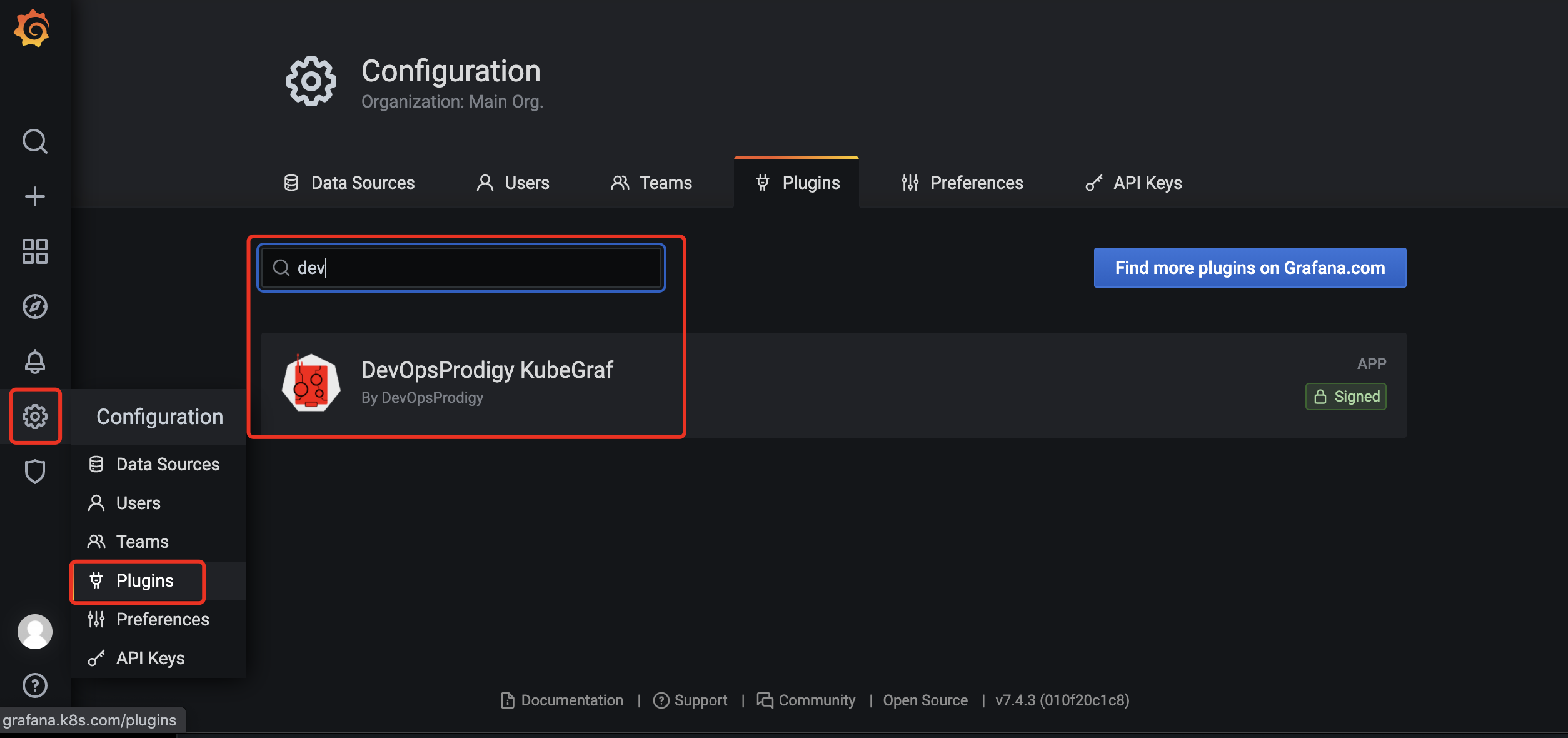
安装插件
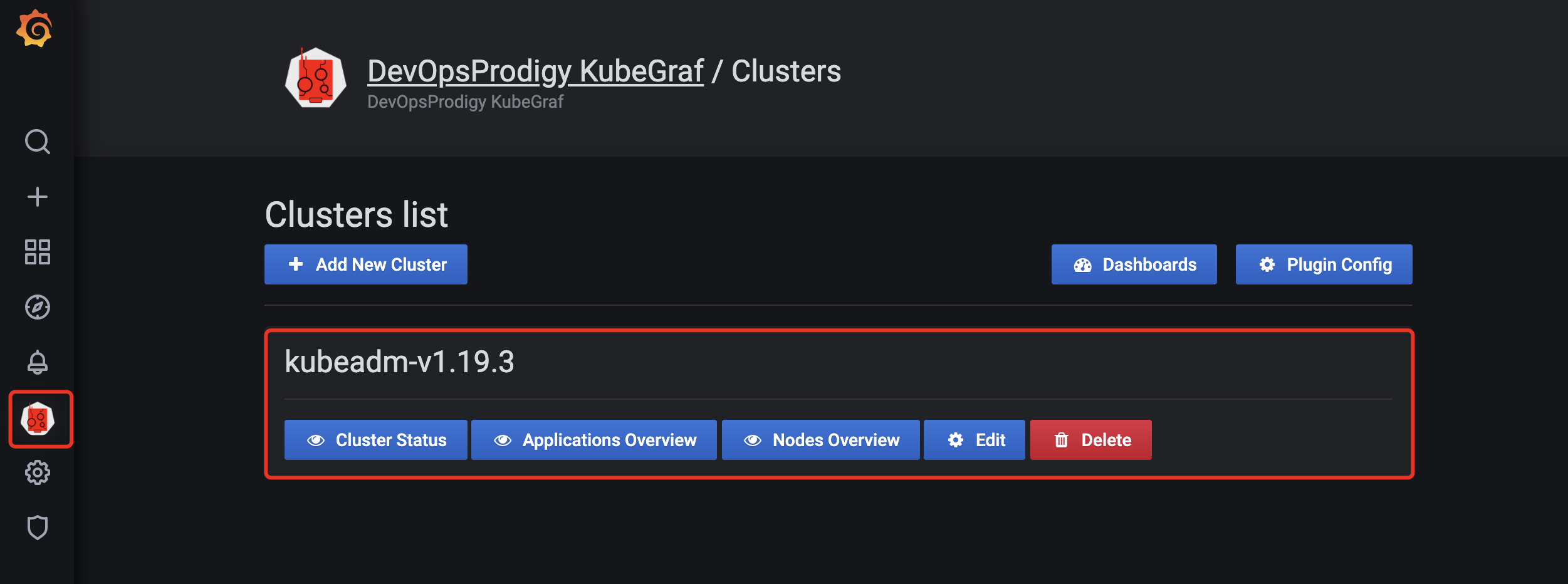
grafana具有丰富的插件,这里我们使用一个非常强大的专门对k8s集群进行监控的插件 :
DevOpsProdigy KubeGraf 项目地址为:
https://github.com/devopsprodigy/kubegraf/
https://github.com/devopsprodigy/kubegraf-v2
安装这个插件需要我们进入grafana的pod内进行安装:
[root@node1 prom]# kubectl -n prom exec -it grafana-7f5b7455fc-z6ctx -- /bin/bash
bash-5.0# grafana-cli plugins install devopsprodigy-kubegraf-app
installing devopsprodigy-kubegraf-app @ 1.5.2
from: https://grafana.com/api/plugins/devopsprodigy-kubegraf-app/versions/1.5.2/download
into: /var/lib/grafana/plugins
✔ Installed devopsprodigy-kubegraf-app successfully
installing grafana-piechart-panel @ 1.6.2
from: https://grafana.com/api/plugins/grafana-piechart-panel/versions/1.6.2/download
into: /var/lib/grafana/plugins
✔ Installed grafana-piechart-panel successfully
Installed dependency: grafana-piechart-panel ✔
Restart grafana after installing plugins . <service grafana-server restart>
bash-5.0#
安装完成后我们还需要重启一下grafana才能生效,因为我们做了数据持久化,所以直接删除pod重新创建即可。
[root@node1 prom]# kubectl -n prom delete pod grafana-7f5b7455fc-z6ctx
pod "grafana-7f5b7455fc-z6ctx" deleted
重启之后我们在grafana页面激活插件
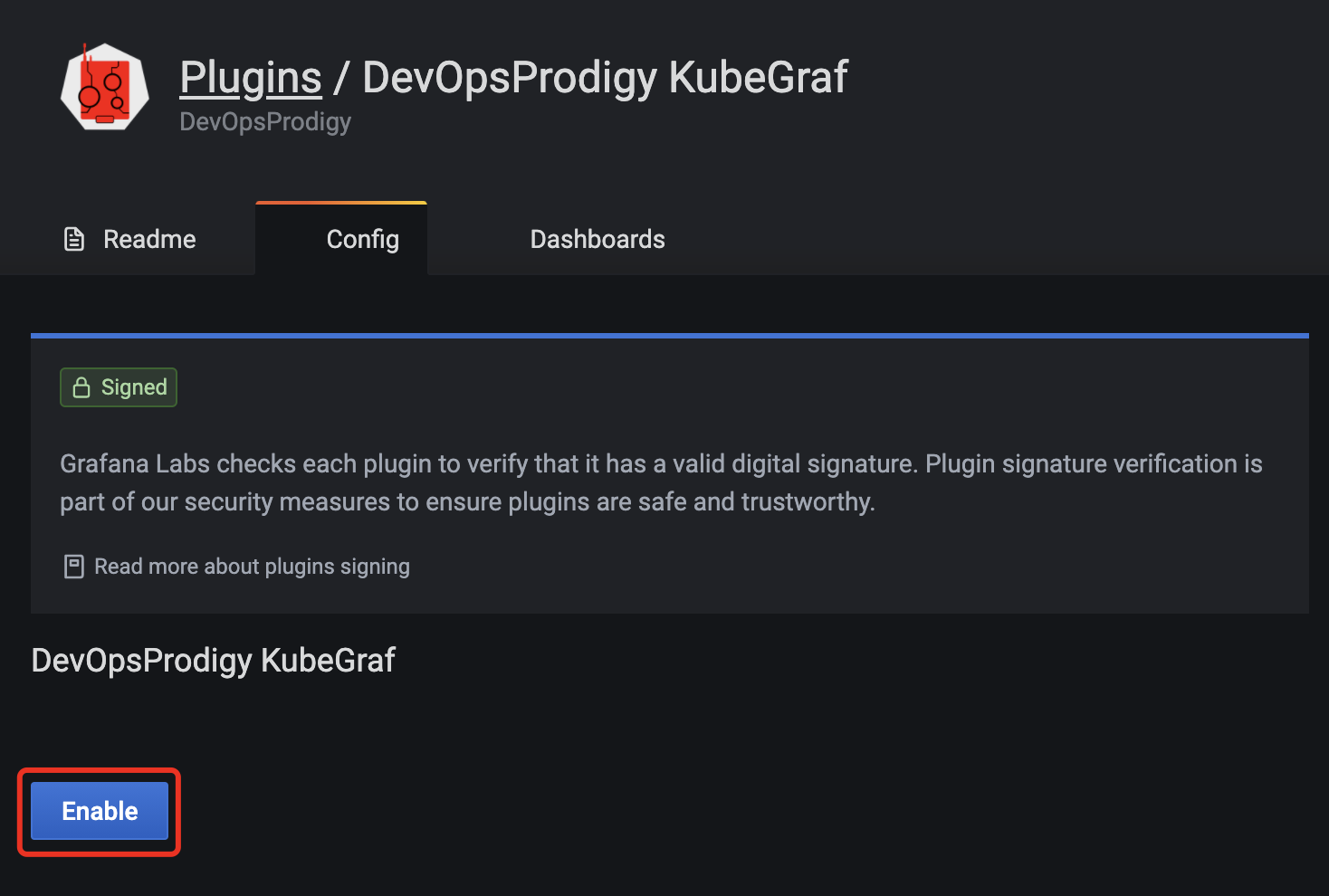
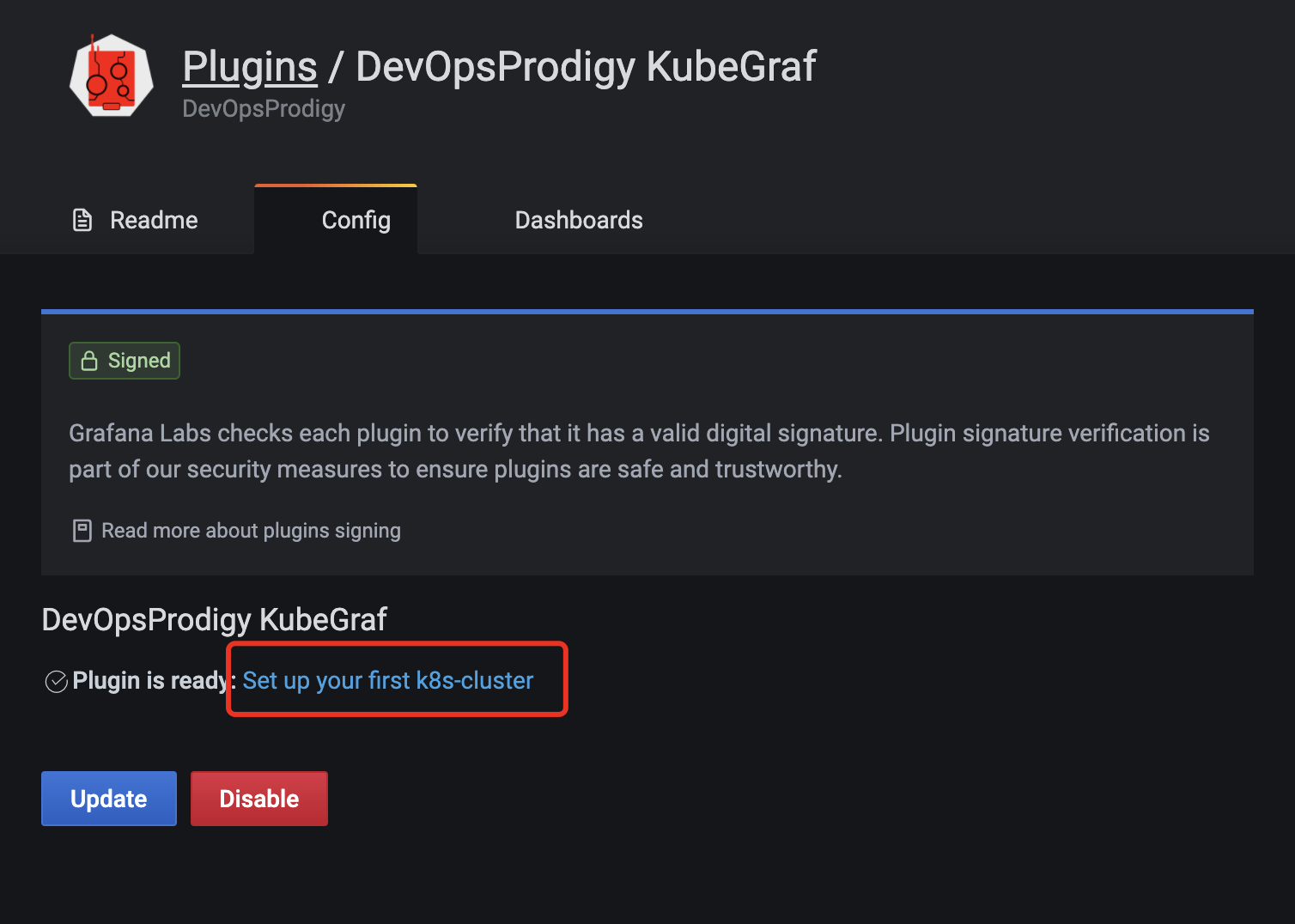
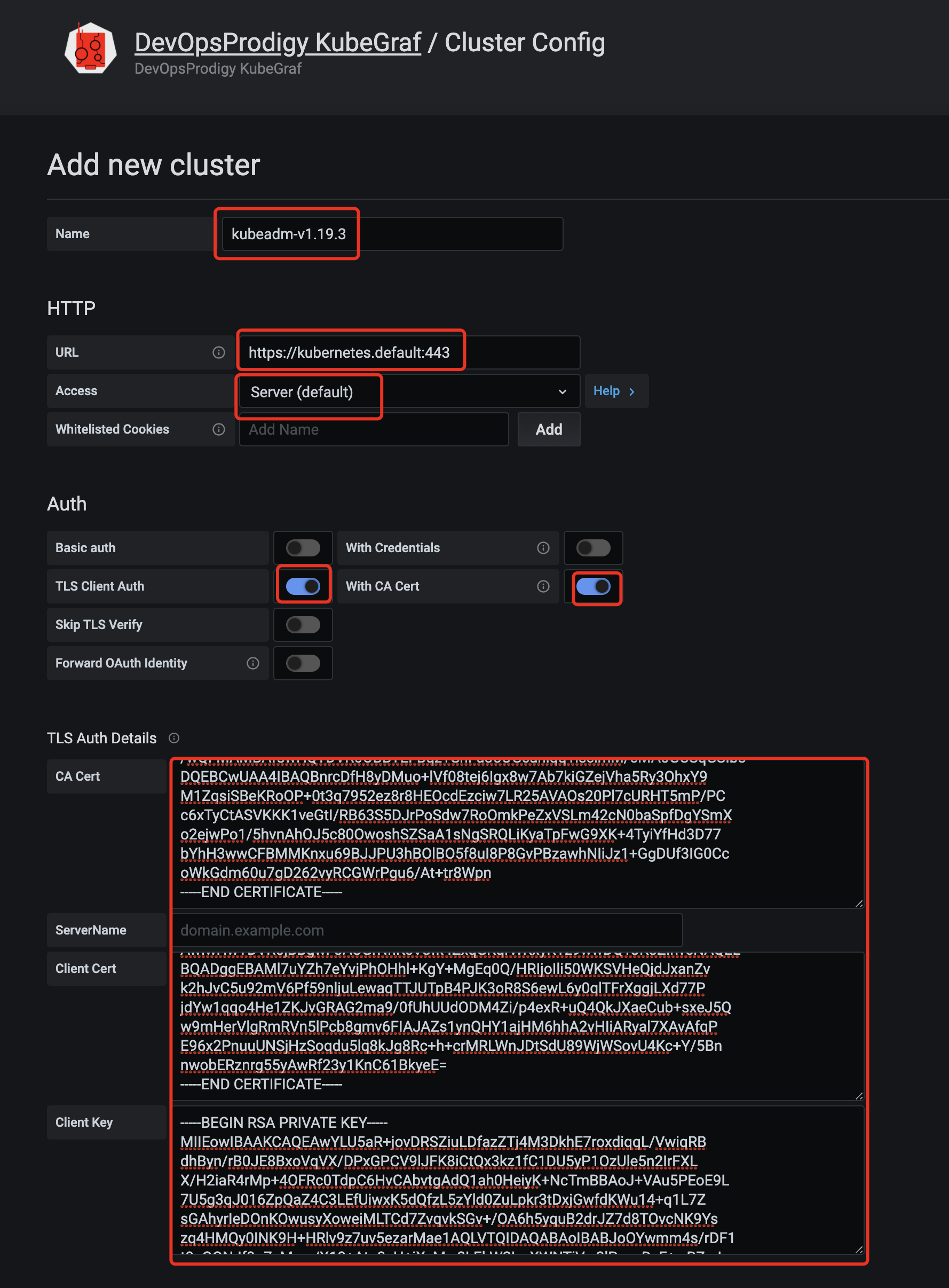
这里需要对验证,我们使用kubectl的kubeconfig配置文件的内容来进行配置:
[root@node1 prom]# cat ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: #CA Cert的值
..............
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: #Client Cert的值
client-key-data: #Client Key的值
..............
但是配置文件里的为base64编码后的,所以我们还需要进行解码,配置完成后的截图如下:干!你写完整能!!@#!@%#
保存之后左边就会出现插件的图标,点击就可以查看了
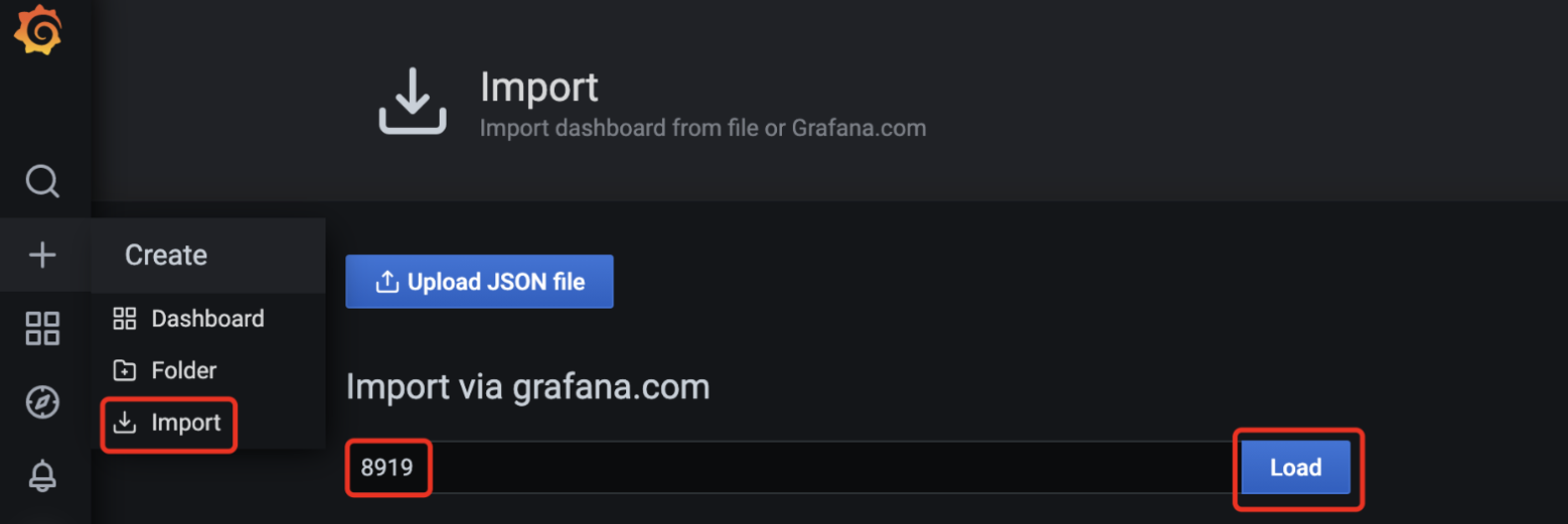
导入dashboard
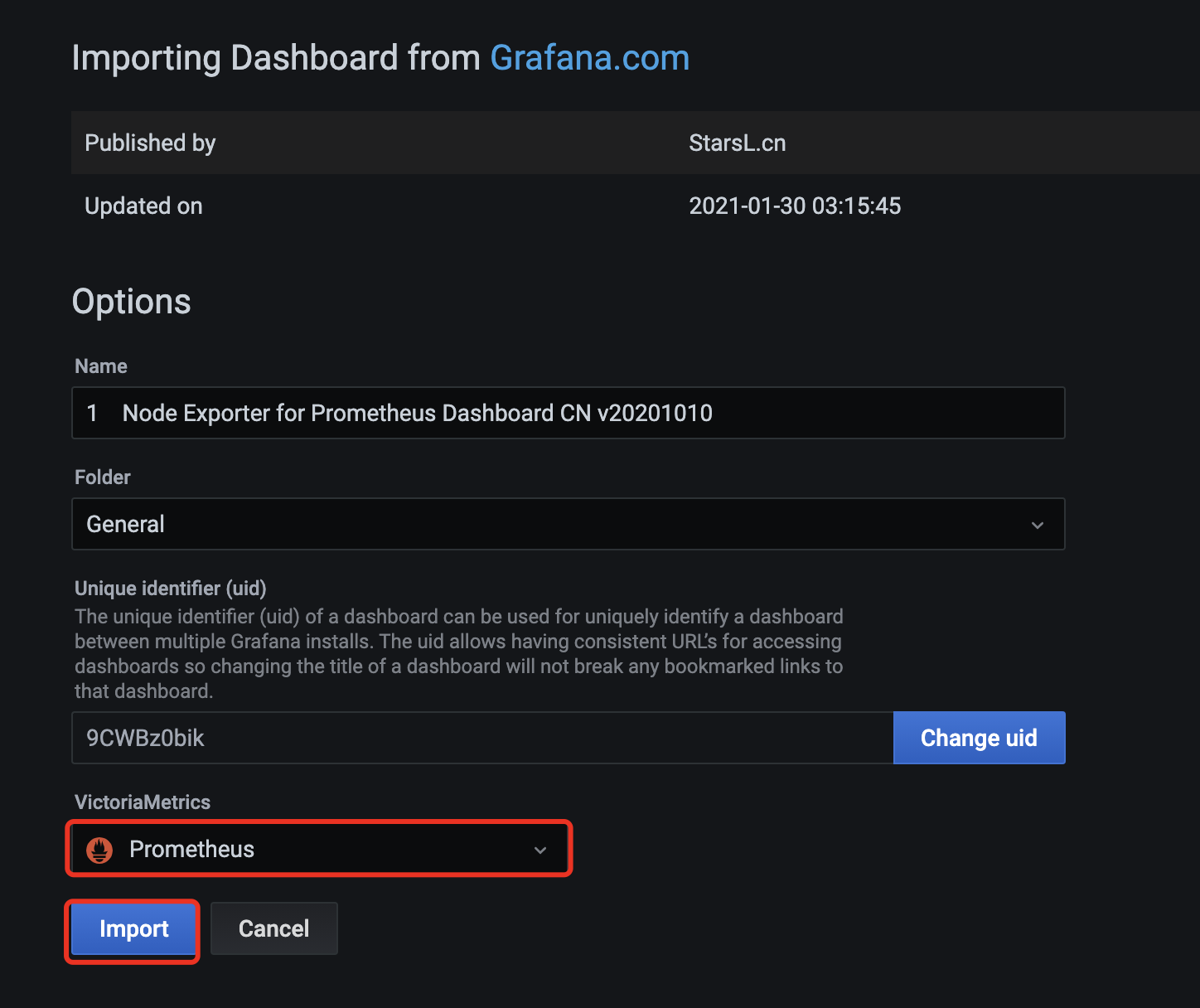
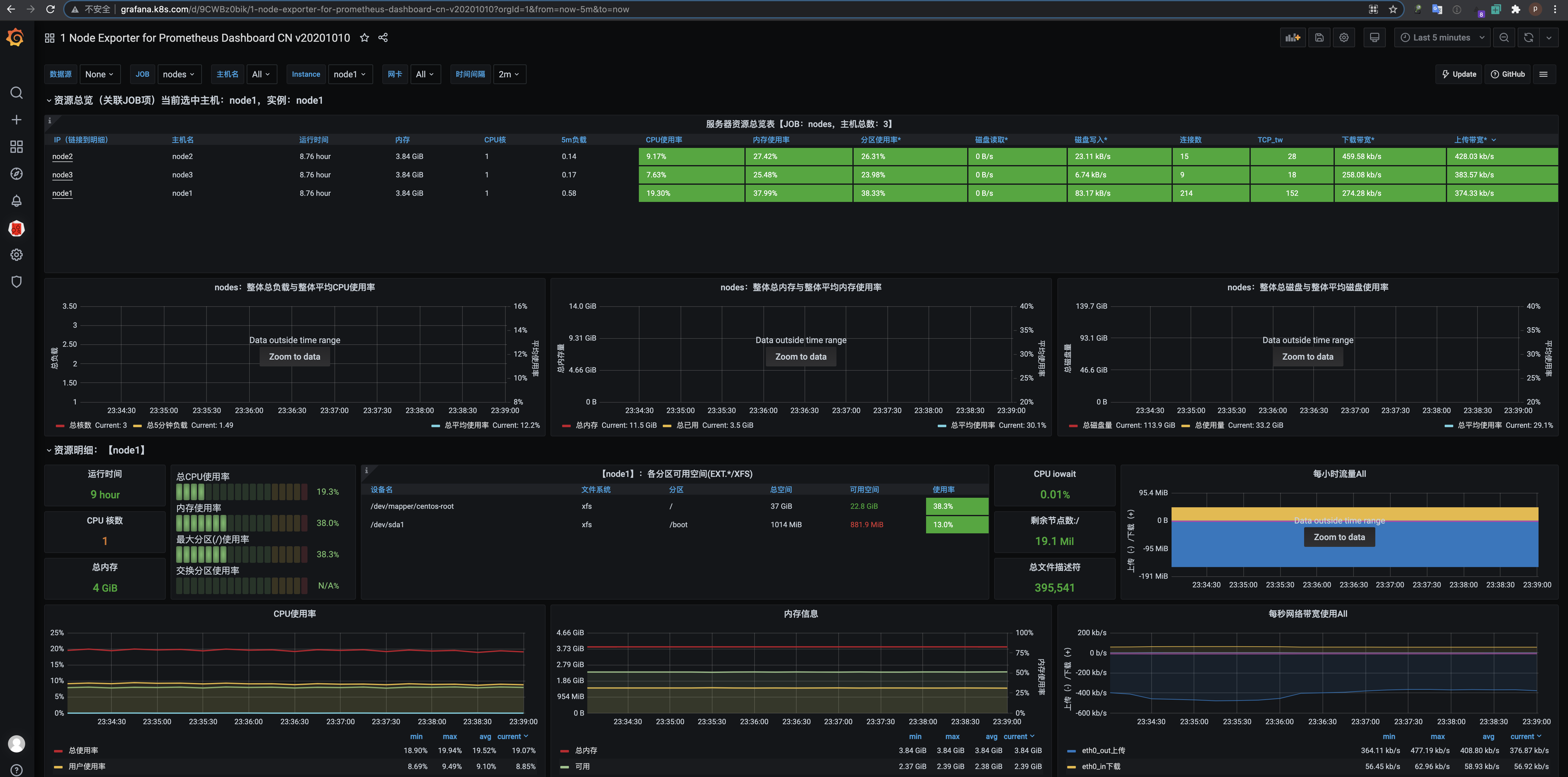
当我们下载别人的dashboard时经常会遇到图形显示错乱或者数据异常,这是因为作者制作的图形的数据源和采集信息和我们部署的prometheus版本不一样或者不匹配,我们可以通过修改采集语句的变量来调整。
https://grafana.com/grafana/dashboards/16098-1-node-exporter-for-prometheus-dashboard-cn-0417-job/
比如这个dashboard作者说有一个指标需要单独填写规则
cm:
global:
scrape_interval: 15s
scrape_timeout: 15s
# 新增加规则文件
rule_files:
- 'node_rules.yml'
...
# 新增加以下配置
node_rules.yml: |
groups:
- name: node_usage_record_rules
interval: 1m
rules:
- record: cpu:usage:rate1m
expr: (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[3m])) by (job,instance)) * 100
- record: mem:usage:rate1m
expr: (1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100
重新生效后查看prometheus配置:

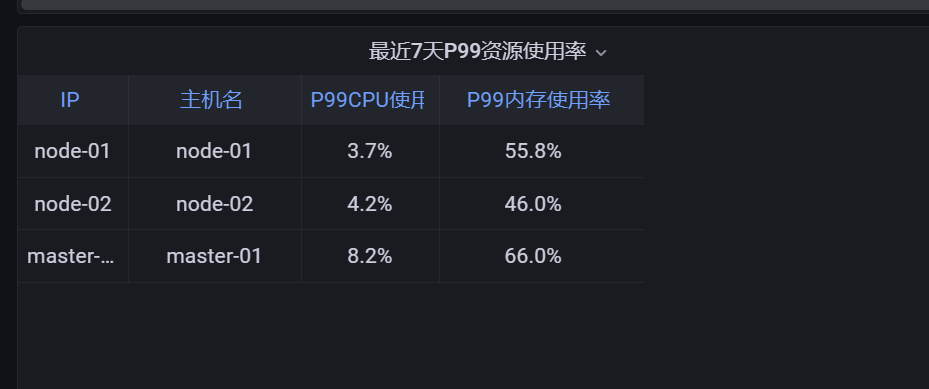
修改dashboard的图表语句:
quantile_over_time(0.99, cpu:usage:rate1m{origin_prometheus=~"$origin_prometheus",job=~"$job",}[$interval])
quantile_over_time(0.99, mem:usage:rate1m{origin_prometheus=~"$origin_prometheus",job=~"$job"}[$interval])
更新: 2024-09-21 16:14:11