第5章alertmanager
第5章 Alertmanager报警
Prometheus告警规则
prometheus告警规则由以下部分组成
- 告警名称:告警任务的名字
- 告警规则:就是具体报警的PromQ查询的结果持续多久后(During)触发报警
报警介质:
- 邮件
- 钉钉
- 飞书
安装
cat > alertmanager.yml << 'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: prom
data:
config.yml: |-
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '526195417@qq.com'
smtp_auth_username: '526195417@qq.com'
smtp_auth_password: 'mtbxhvaqonvrbgia'
smtp_hello: 'qq.com'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 相同的group之间发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送他们,不同类型告警发送频率需要具体配置
repeat_interval: 1h
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email
group_wait: 10s
group_by: ['instance'] # 根据instance做分组
match:
team: node
receivers:
- name: 'default'
email_configs:
- to: '526195417@qq.com'
send_resolved: true # 接受告警恢复的通知
- name: 'email'
email_configs:
- to: '526195417@qq.com'
send_resolved: true
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: prom
labels:
app: alertmanager
spec:
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
volumes:
- name: alertcfg
configMap:
name: alert-config
containers:
- name: alertmanager
image: prom/alertmanager:v0.21.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: alertcfg
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: prom
labels:
app: alertmanager
spec:
selector:
app: alertmanager
ports:
- name: web
port: 9093
targetPort: http
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: alertmanager
namespace: prom
labels:
app: alertmanager
spec:
rules:
- host: alertmanager.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: alertmanager
port:
number: 9093
EOF
应用配置:
[root@node1 prom]# kubectl apply -f alertmanager.yml
configmap/alert-config created
deployment.apps/alertmanager created
service/alertmanager created
ingress.networking.k8s.io/alertmanager created
访问查看
配置报警规则
编写报警规则
cat > prom-cm.yml << 'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: prom
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
evaluation_interval: 30s # 默认情况下每分钟对告警规则进行计算
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"]
rule_files:
- /etc/prometheus/rules.yml
scrape_configs:
.........其他配置..........
rules.yml: |
groups:
- name: test-node-mem
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 20
for: 2m
labels:
team: node
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 20% (current value is: {{ $value }}"
EOF
报警规则解释
一条报警规则主要由以下几部分组成:
- alert:告警规则的名称
- expr:报警规则的PromQL查询语句
- for:评估等待时间 (Pending Duration),触发后持续多久后才发送,等待期间的告警状态为pending
- labels:自定义标签,可以附加在告警上
- annotations:指定另一组标签,用于报警信息展示,可以通过$labels引用标签的值
- summary:报警主题
- description:具体的报警内容
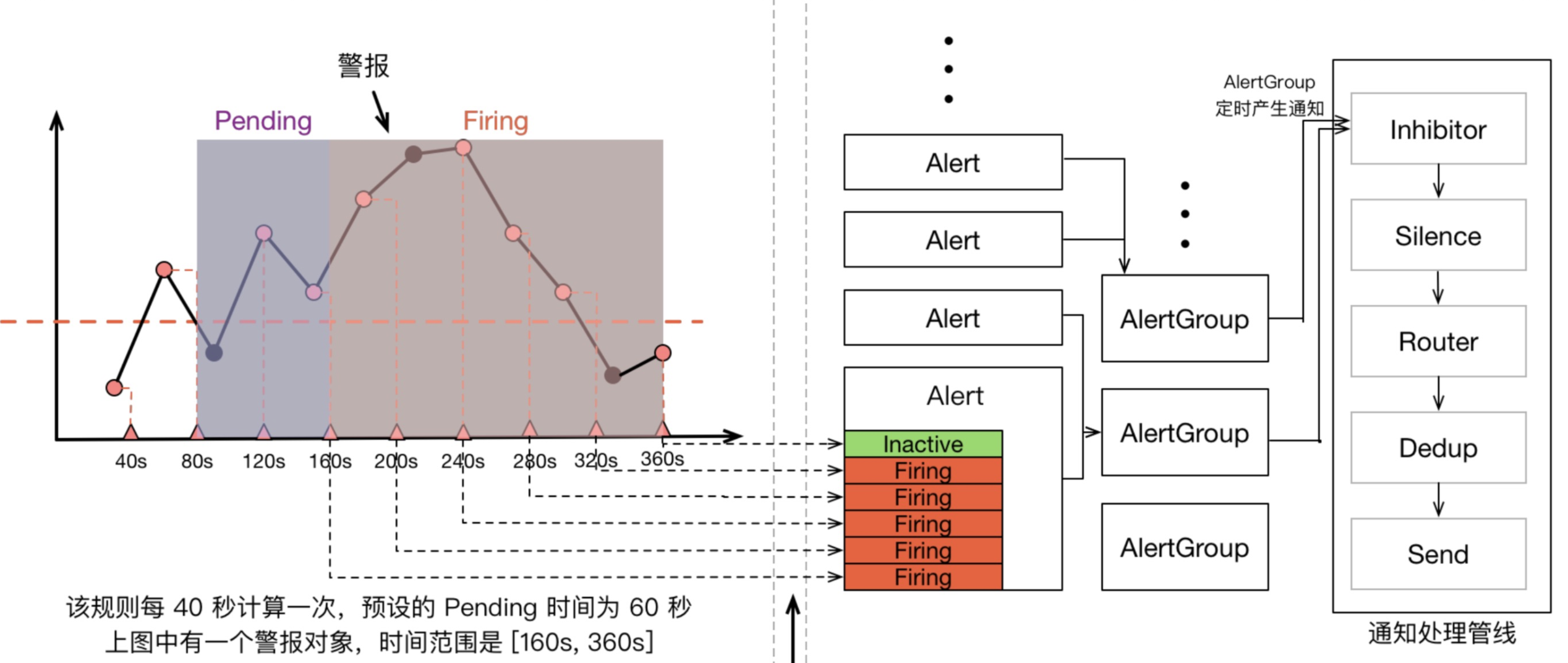
报警状态解释
- pending: 表示在设置的阈值时间范围内被激活了
- firing: 表示超过设置的阈值时间被激活了
- inactive: 表示当前报警信息处于非活动状态
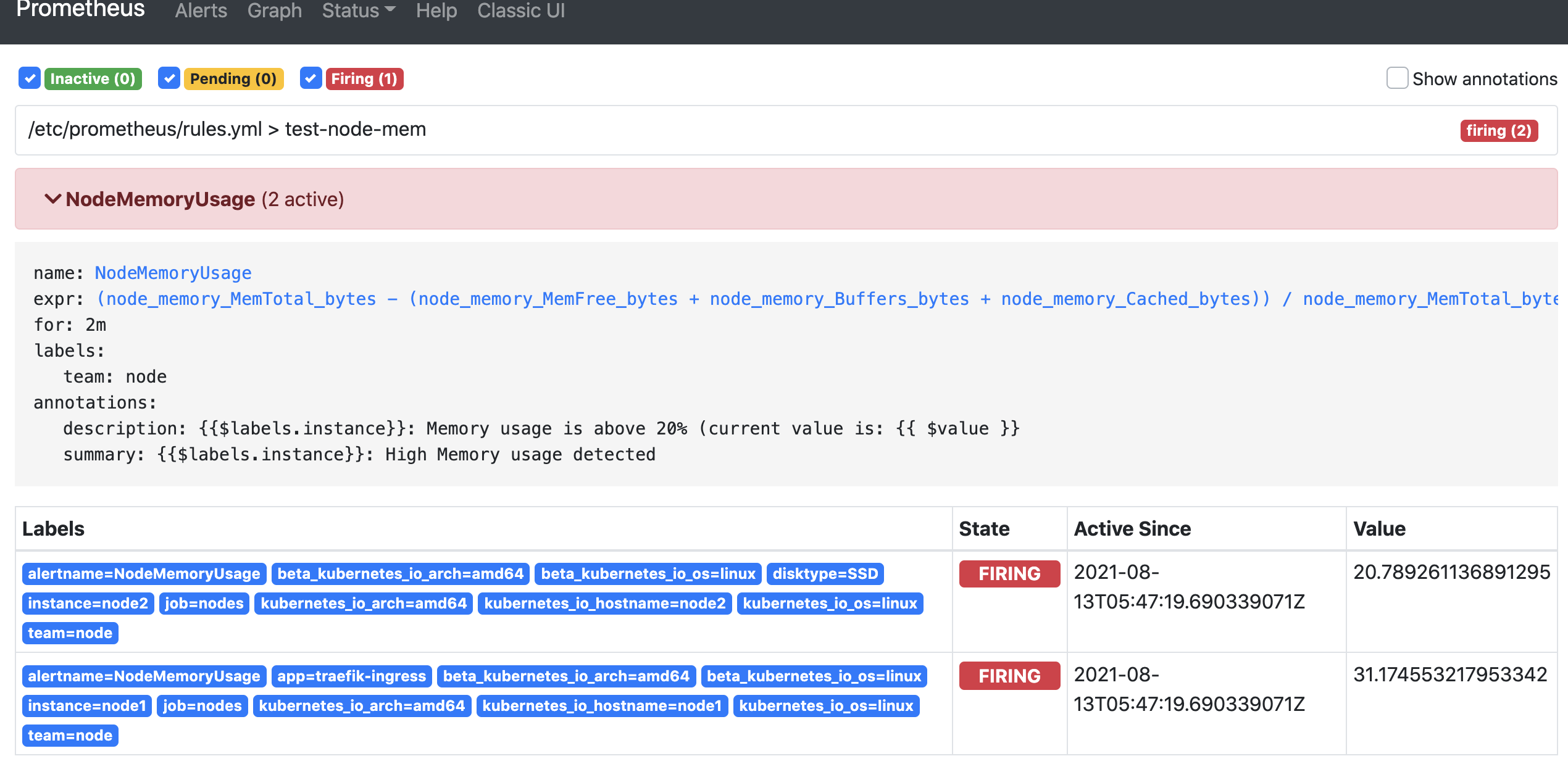
报警效果

报警概念
访问Altermanager页面可以查看报警详情
这里有两个新的概念
- Inhibition: 抑制 简单来说就是避免连锁反应
- Sliences: 静默 指定时间简单的忽略所有警报
第x章 报警规则收集
报警规则非常全的网站:
https://awesome-prometheus-alerts.grep.to/rules
举例:添加磁盘的报警规则:
修改prom-cm配置:
rules.yml: |
groups:
- name: test-node-mem
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 20
for: 2m
labels:
team: node
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 20% (current value is: {{ $value }}"
- alert: HostOutOfDiskSpace
expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0
for: 2m
labels:
severity: warning
annotations:
summary: Host out of disk space (instance {{ $labels.instance }})
description: "Disk is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
重启并加载即可
第x章 自定义邮件告警模版
alert配置文件
https://prometheus.io/docs/alerting/latest/configuration/
默认的告警模版:
https://raw.githubusercontent.com/prometheus/alertmanager/master/template/default.tmpl
如果自定义邮件告警:
...
config.yml: |-
templates:
- '/etc/alertmanager/template_email.tmpl'
...
receivers:
- name: 'email'
email_configs:
- to: 'vim27@qq.com'
send_resolved: true
html: '{{ template "email.template" . }}'
...
template_email.tmpl: |-
{{ define "email.template" }}
{{ range .Alerts }}
{{ if eq .Status "firing" }}
<h3>告警级别:{{ .Labels.severity }}</h3>
<h3>告警概述:{{ .Annotations.summary }}</h3>
<h3>告警详情:{{ .Annotations.description }}</h3>
<h3>报警实例:{{ .Labels.instance }}</h3>
<h3>开始时间:{{ .StartsAt.Format "2006-01-02 15:04:05" }}</h3>
{{ else if eq .Status "resolved" }}
<h3>恢复概述:{{ .Annotations.summary }}</h3>
<h3>恢复实例:{{ .Labels.instance }}</h3>
<h3>恢复时间:{{ .EndsAt.Format "2006-01-02 15:04:05" }}</h3>
{{ end }}
{{ end }}
{{ end }}
更新: 2024-09-23 14:09:48